 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Multilingual Training of Neural Dependency Parsers
Paper and Code
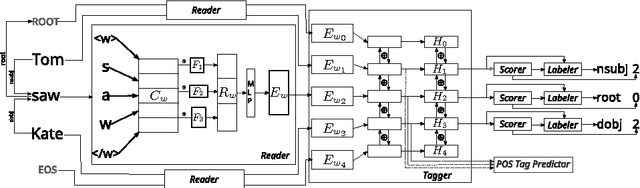
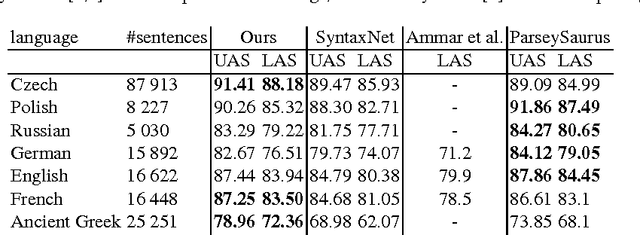
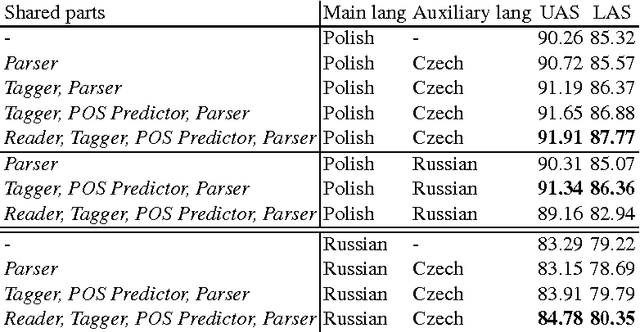

We show that a recently proposed neural dependency parser can be improved by joint training on multiple languages from the same family. The parser is implemented as a deep neural network whose only input is orthographic representations of words. In order to successfully parse, the network has to discover how linguistically relevant concepts can be inferred from word spellings. We analyze the representations of characters and words that are learned by the network to establish which properties of languages were accounted for. In particular we show that the parser has approximately learned to associate Latin characters with their Cyrillic counterparts and that it can group Polish and Russian words that have a similar grammatical function. Finally, we evaluate the parser on selected languages from the Universal Dependencies dataset and show that it is competitive with other recently proposed state-of-the art methods, while having a simple structure.