 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient and principled score estimation with Nyström kernel exponential families
Paper and Code
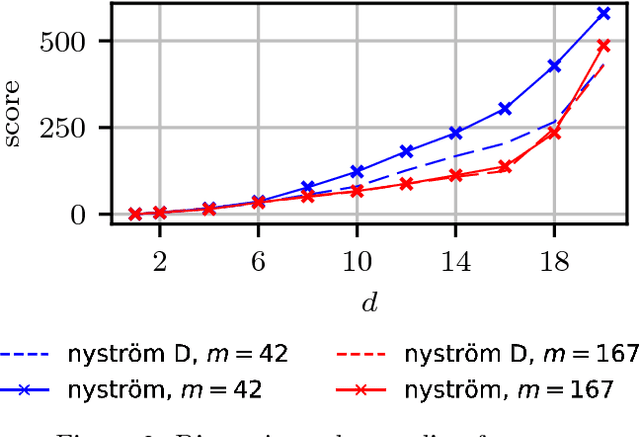
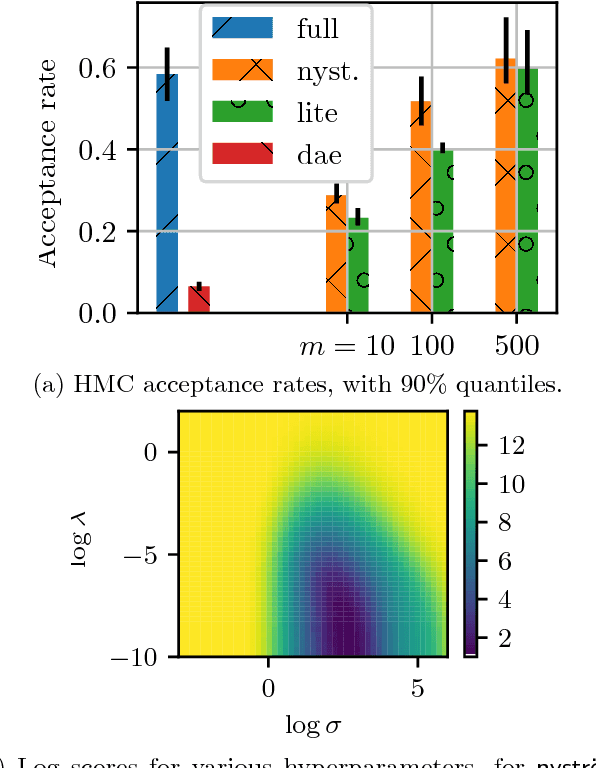
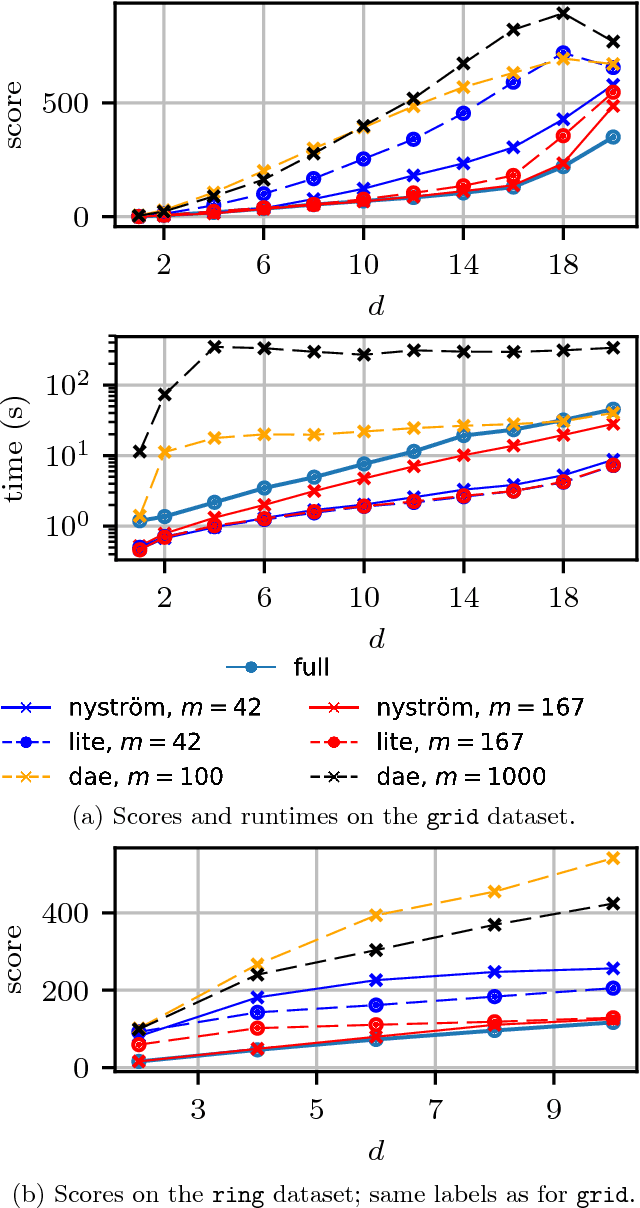
We propose a fast method with statistical guarantees for learning an exponential family density model where the natural parameter is in a reproducing kernel Hilbert space, and may be infinite-dimensional. The model is learned by fitting the derivative of the log density, the score, thus avoiding the need to compute a normalization constant. Our approach improves the computational efficiency of an earlier solution by using a low-rank, Nystr\"om-like solution. The new solution retains the consistency and convergence rates of the full-rank solution (exactly in Fisher distance, and nearly in other distances), with guarantees on the degree of cost and storage reduction. We evaluate the method in experiments on density estimation and in the construction of an adaptive Hamiltonian Monte Carlo sampler. Compared to an existing score learning approach using a denoising autoencoder, our estimator is empirically more data-efficient when estimating the score, runs faster, and has fewer parameters (which can be tuned in a principled and interpretable way), in addition to providing statistical guarantees.