 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo-temperature logistic regression based on the Tsallis divergence
Paper and Code
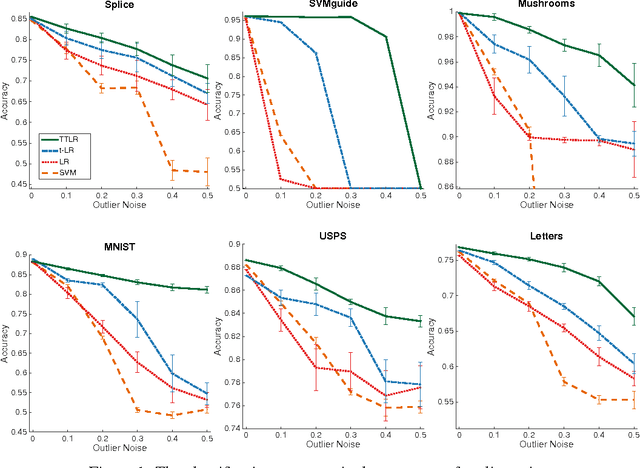
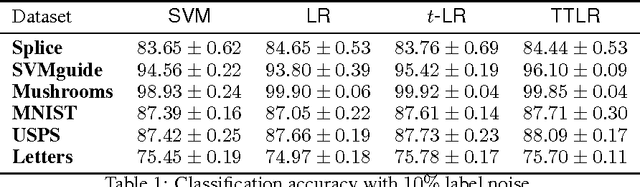
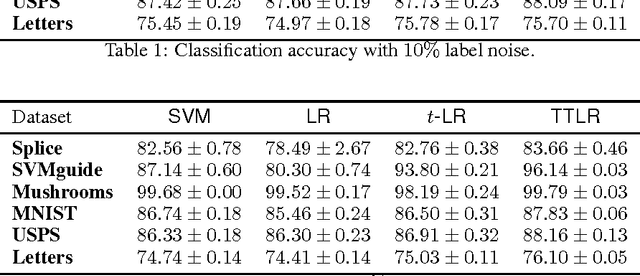
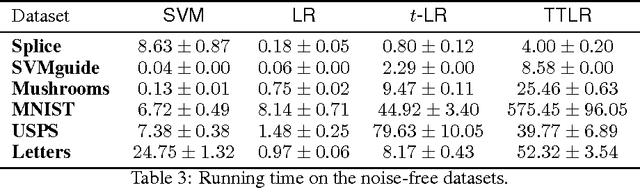
We develop a variant of multiclass logistic regression that achieves three properties: i) We minimize a non-convex surrogate loss which makes the method robust to outliers, ii) our method allows transitioning between non-convex and convex losses by the choice of the parameters, iii) the surrogate loss is Bayes consistent, even in the non-convex case. The algorithm has one weight vector per class and the surrogate loss is a function of the linear activations (one per class). The surrogate loss of an example with linear activation vector $\mathbf{a}$ and class $c$ has the form $-\log_{t_1} \exp_{t_2} (a_c - G_{t_2}(\mathbf{a}))$ where the two temperatures $t_1$ and $t_2$ "temper" the $\log$ and $\exp$, respectively, and $G_{t_2}$ is a generalization of the log-partition function. We motivate this loss using the Tsallis divergence. As the temperature of the logarithm becomes smaller than the temperature of the exponential, the surrogate loss becomes "more quasi-convex". Various tunings of the temperatures recover previous methods and tuning the degree of non-convexity is crucial in the experiments. The choice $t_1<1$ and $t_2>1$ performs best experimentally. We explain this by showing that $t_1 < 1$ caps the surrogate loss and $t_2 >1$ makes the predictive distribution have a heavy tail.