 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding effective deep neural network architectures one feature at a time
Paper and Code
Oct 19, 2017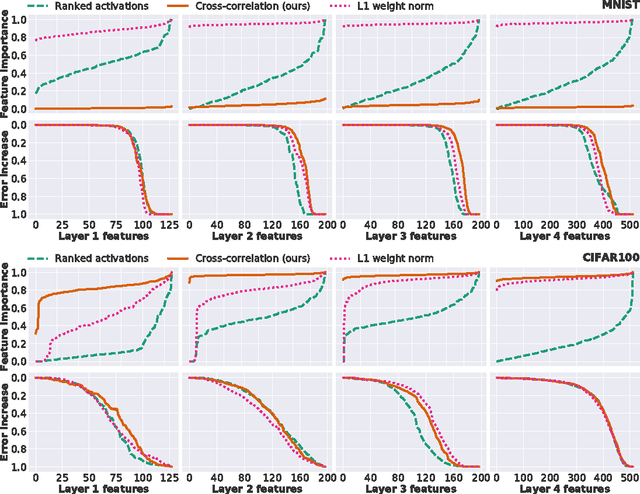
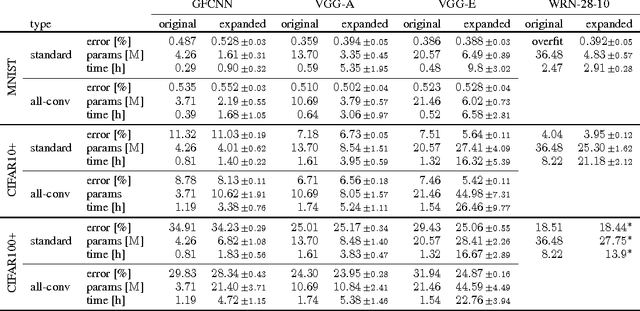
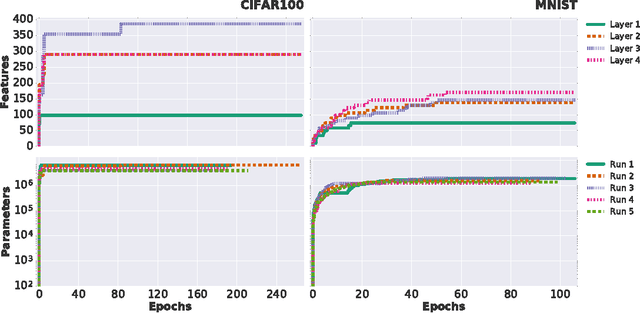

Successful training of convolutional neural networks is often associated with sufficiently deep architectures composed of high amounts of features. These networks typically rely on a variety of regularization and pruning techniques to converge to less redundant states. We introduce a novel bottom-up approach to expand representations in fixed-depth architectures. These architectures start from just a single feature per layer and greedily increase width of individual layers to attain effective representational capacities needed for a specific task. While network growth can rely on a family of metrics, we propose a computationally efficient version based on feature time evolution and demonstrate its potency in determining feature importance and a networks' effective capacity. We demonstrate how automatically expanded architectures converge to similar topologies that benefit from lesser amount of parameters or improved accuracy and exhibit systematic correspondence in representational complexity with the specified task. In contrast to conventional design patterns with a typical monotonic increase in the amount of features with increased depth, we observe that CNNs perform better when there is more learnable parameters in intermediate, with falloffs to earlier and later layers.