 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredictive-Corrective Networks for Action Detection
Paper and Code
Dec 12, 2017
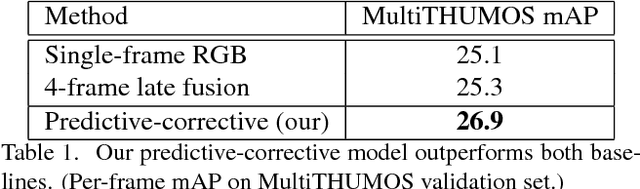
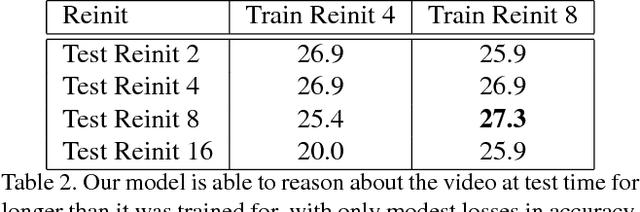
While deep feature learning has revolutionized techniques for static-image understanding, the same does not quite hold for video processing. Architectures and optimization techniques used for video are largely based off those for static images, potentially underutilizing rich video information. In this work, we rethink both the underlying network architecture and the stochastic learning paradigm for temporal data. To do so, we draw inspiration from classic theory on linear dynamic systems for modeling time series. By extending such models to include nonlinear mappings, we derive a series of novel recurrent neural networks that sequentially make top-down predictions about the future and then correct those predictions with bottom-up observations. Predictive-corrective networks have a number of desirable properties: (1) they can adaptively focus computation on "surprising" frames where predictions require large corrections, (2) they simplify learning in that only "residual-like" corrective terms need to be learned over time and (3) they naturally decorrelate an input data stream in a hierarchical fashion, producing a more reliable signal for learning at each layer of a network. We provide an extensive analysis of our lightweight and interpretable framework, and demonstrate that our model is competitive with the two-stream network on three challenging datasets without the need for computationally expensive optical flow.