 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeceiving Google's Cloud Video Intelligence API Built for Summarizing Videos
Paper and Code
Mar 31, 2017
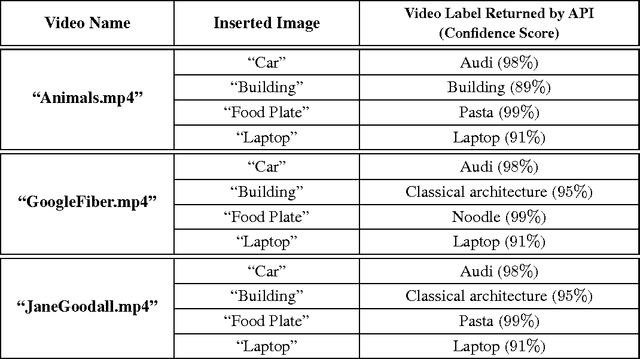

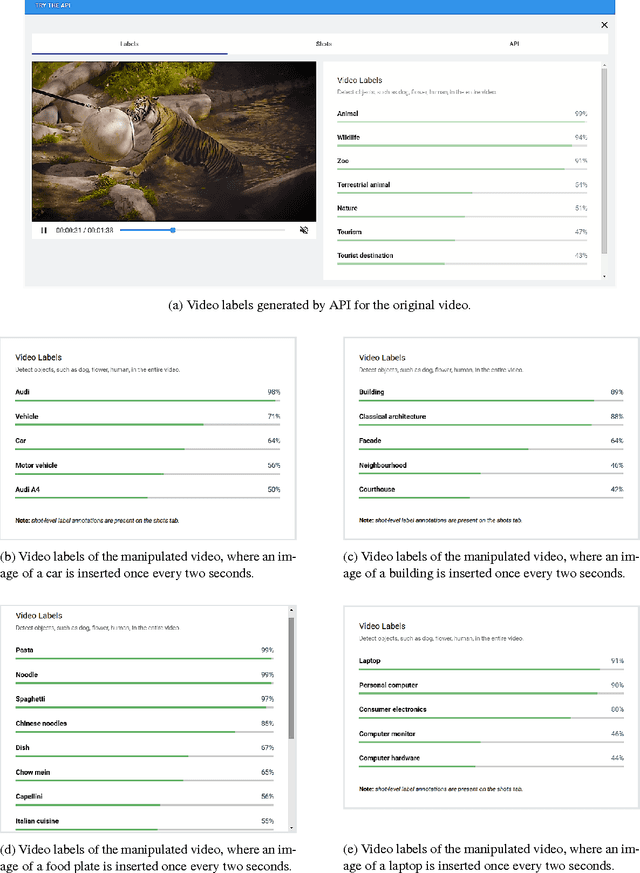
Despite the rapid progress of the techniques for image classification, video annotation has remained a challenging task. Automated video annotation would be a breakthrough technology, enabling users to search within the videos. Recently, Google introduced the Cloud Video Intelligence API for video analysis. As per the website, the system can be used to "separate signal from noise, by retrieving relevant information at the video, shot or per frame" level. A demonstration website has been also launched, which allows anyone to select a video for annotation. The API then detects the video labels (objects within the video) as well as shot labels (description of the video events over time). In this paper, we examine the usability of the Google's Cloud Video Intelligence API in adversarial environments. In particular, we investigate whether an adversary can subtly manipulate a video in such a way that the API will return only the adversary-desired labels. For this, we select an image, which is different from the video content, and insert it, periodically and at a very low rate, into the video. We found that if we insert one image every two seconds, the API is deceived into annotating the video as if it only contained the inserted image. Note that the modification to the video is hardly noticeable as, for instance, for a typical frame rate of 25, we insert only one image per 50 video frames. We also found that, by inserting one image per second, all the shot labels returned by the API are related to the inserted image. We perform the experiments on the sample videos provided by the API demonstration website and show that our attack is successful with different videos and images.