 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWho Said What: Modeling Individual Labelers Improves Classification
Paper and Code
Jan 04, 2018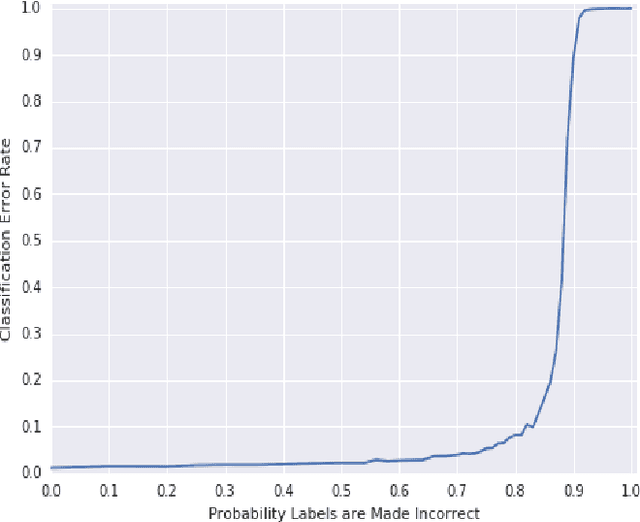
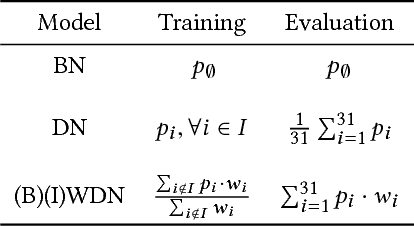
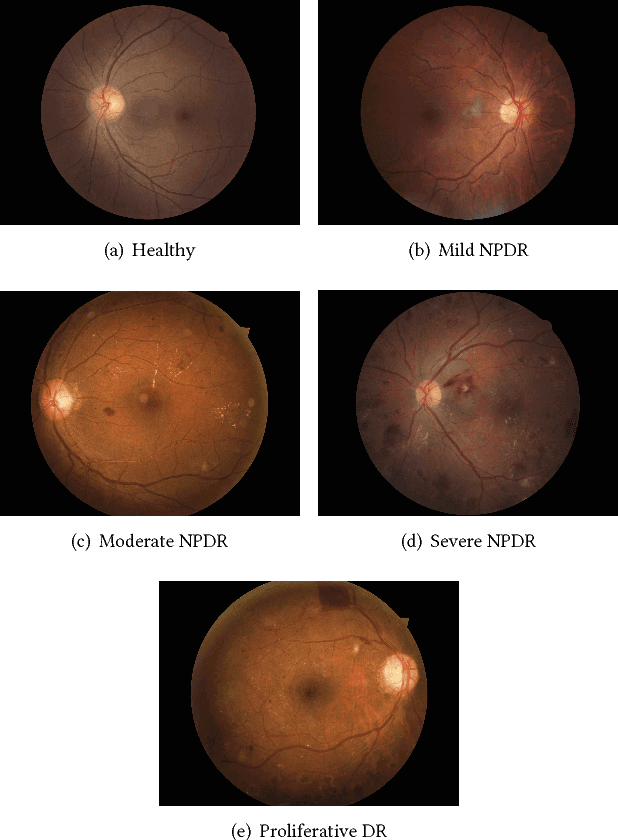
Data are often labeled by many different experts with each expert only labeling a small fraction of the data and each data point being labeled by several experts. This reduces the workload on individual experts and also gives a better estimate of the unobserved ground truth. When experts disagree, the standard approaches are to treat the majority opinion as the correct label or to model the correct label as a distribution. These approaches, however, do not make any use of potentially valuable information about which expert produced which label. To make use of this extra information, we propose modeling the experts individually and then learning averaging weights for combining them, possibly in sample-specific ways. This allows us to give more weight to more reliable experts and take advantage of the unique strengths of individual experts at classifying certain types of data. Here we show that our approach leads to improvements in computer-aided diagnosis of diabetic retinopathy. We also show that our method performs better than competing algorithms by Welinder and Perona (2010), and by Mnih and Hinton (2012). Our work offers an innovative approach for dealing with the myriad real-world settings that use expert opinions to define labels for training.