 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDRAGNN: A Transition-based Framework for Dynamically Connected Neural Networks
Paper and Code
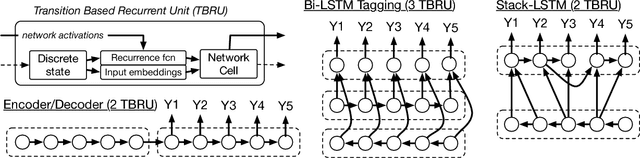
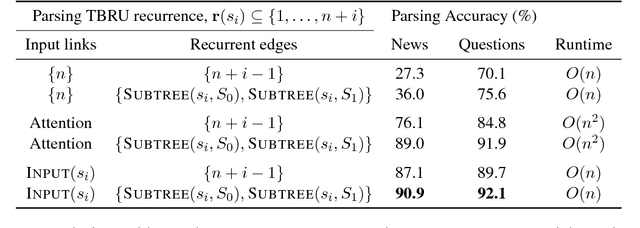
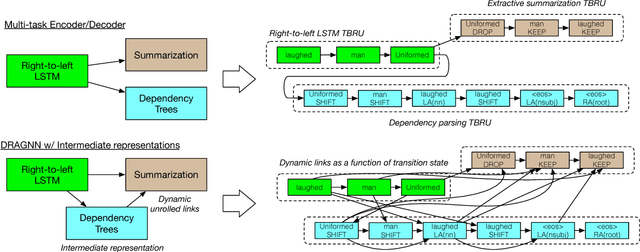

In this work, we present a compact, modular framework for constructing novel recurrent neural architectures. Our basic module is a new generic unit, the Transition Based Recurrent Unit (TBRU). In addition to hidden layer activations, TBRUs have discrete state dynamics that allow network connections to be built dynamically as a function of intermediate activations. By connecting multiple TBRUs, we can extend and combine commonly used architectures such as sequence-to-sequence, attention mechanisms, and re-cursive tree-structured models. A TBRU can also serve as both an encoder for downstream tasks and as a decoder for its own task simultaneously, resulting in more accurate multi-task learning. We call our approach Dynamic Recurrent Acyclic Graphical Neural Networks, or DRAGNN. We show that DRAGNN is significantly more accurate and efficient than seq2seq with attention for syntactic dependency parsing and yields more accurate multi-task learning for extractive summarization tasks.