 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Deep Visual Object Models From Noisy Web Data: How to Make it Work
Paper and Code


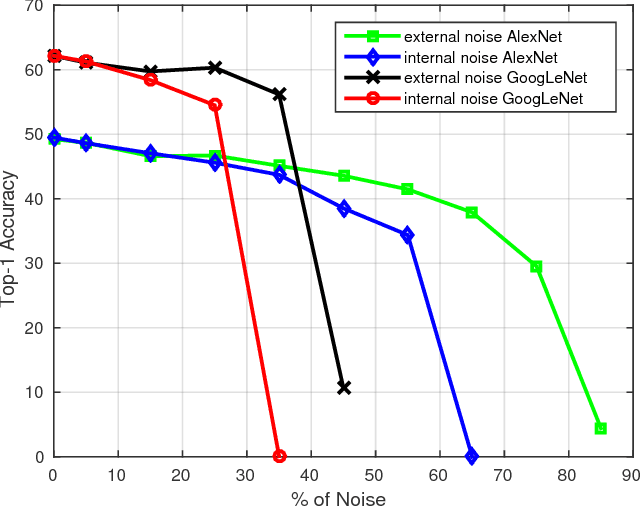
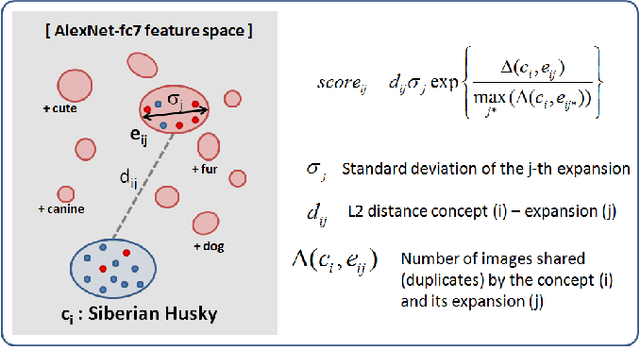
Deep networks thrive when trained on large scale data collections. This has given ImageNet a central role in the development of deep architectures for visual object classification. However, ImageNet was created during a specific period in time, and as such it is prone to aging, as well as dataset bias issues. Moving beyond fixed training datasets will lead to more robust visual systems, especially when deployed on robots in new environments which must train on the objects they encounter there. To make this possible, it is important to break free from the need for manual annotators. Recent work has begun to investigate how to use the massive amount of images available on the Web in place of manual image annotations. We contribute to this research thread with two findings: (1) a study correlating a given level of noisily labels to the expected drop in accuracy, for two deep architectures, on two different types of noise, that clearly identifies GoogLeNet as a suitable architecture for learning from Web data; (2) a recipe for the creation of Web datasets with minimal noise and maximum visual variability, based on a visual and natural language processing concept expansion strategy. By combining these two results, we obtain a method for learning powerful deep object models automatically from the Web. We confirm the effectiveness of our approach through object categorization experiments using our Web-derived version of ImageNet on a popular robot vision benchmark database, and on a lifelong object discovery task on a mobile robot.