 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExemplar-Centered Supervised Shallow Parametric Data Embedding
Paper and Code
Jul 05, 2017
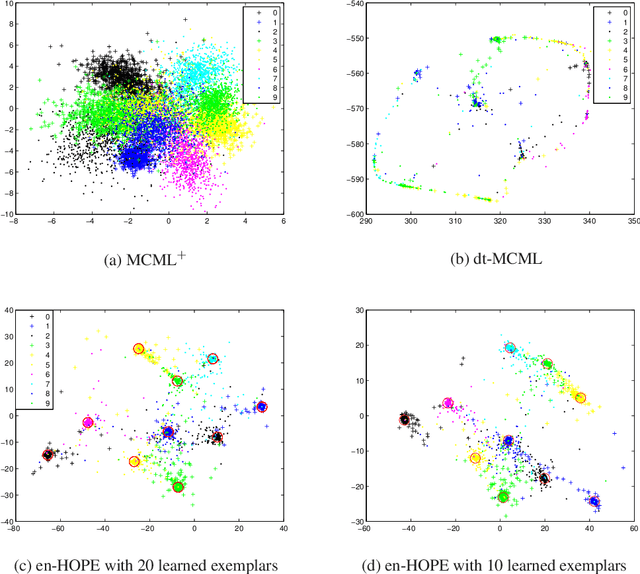
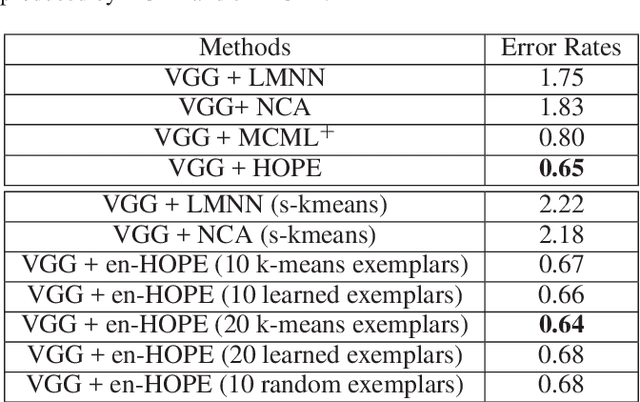
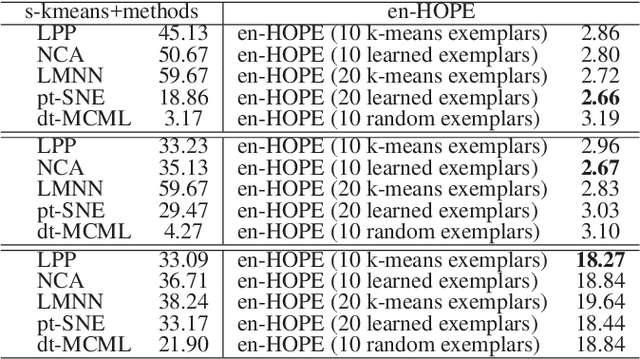
Metric learning methods for dimensionality reduction in combination with k-Nearest Neighbors (kNN) have been extensively deployed in many classification, data embedding, and information retrieval applications. However, most of these approaches involve pairwise training data comparisons, and thus have quadratic computational complexity with respect to the size of training set, preventing them from scaling to fairly big datasets. Moreover, during testing, comparing test data against all the training data points is also expensive in terms of both computational cost and resources required. Furthermore, previous metrics are either too constrained or too expressive to be well learned. To effectively solve these issues, we present an exemplar-centered supervised shallow parametric data embedding model, using a Maximally Collapsing Metric Learning (MCML) objective. Our strategy learns a shallow high-order parametric embedding function and compares training/test data only with learned or precomputed exemplars, resulting in a cost function with linear computational complexity for both training and testing. We also empirically demonstrate, using several benchmark datasets, that for classification in two-dimensional embedding space, our approach not only gains speedup of kNN by hundreds of times, but also outperforms state-of-the-art supervised embedding approaches.