 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHemingway: Modeling Distributed Optimization Algorithms
Paper and Code
Feb 20, 2017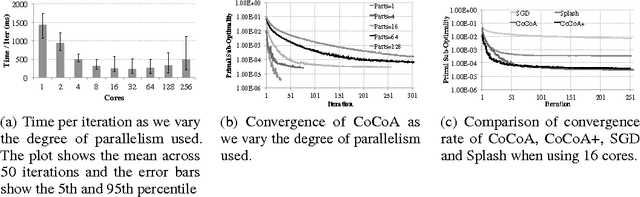
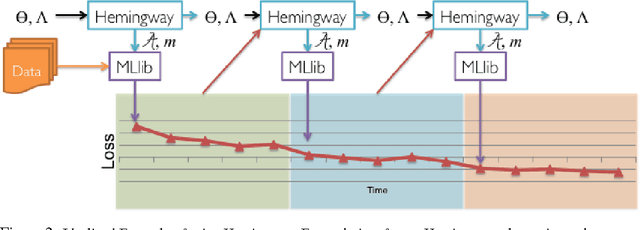
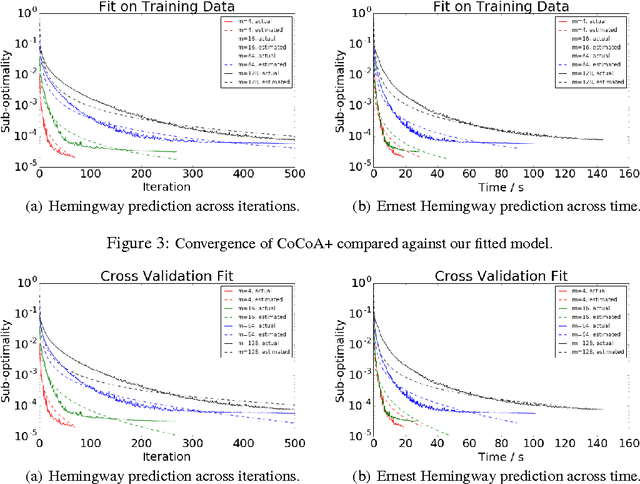
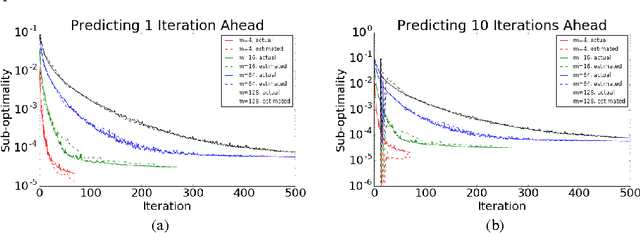
Distributed optimization algorithms are widely used in many industrial machine learning applications. However choosing the appropriate algorithm and cluster size is often difficult for users as the performance and convergence rate of optimization algorithms vary with the size of the cluster. In this paper we make the case for an ML-optimizer that can select the appropriate algorithm and cluster size to use for a given problem. To do this we propose building two models: one that captures the system level characteristics of how computation, communication change as we increase cluster sizes and another that captures how convergence rates change with cluster sizes. We present preliminary results from our prototype implementation called Hemingway and discuss some of the challenges involved in developing such a system.