 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation Pursuit: A Bayesian Framework for Sequential Scene Parsing
Paper and Code
Jan 09, 2017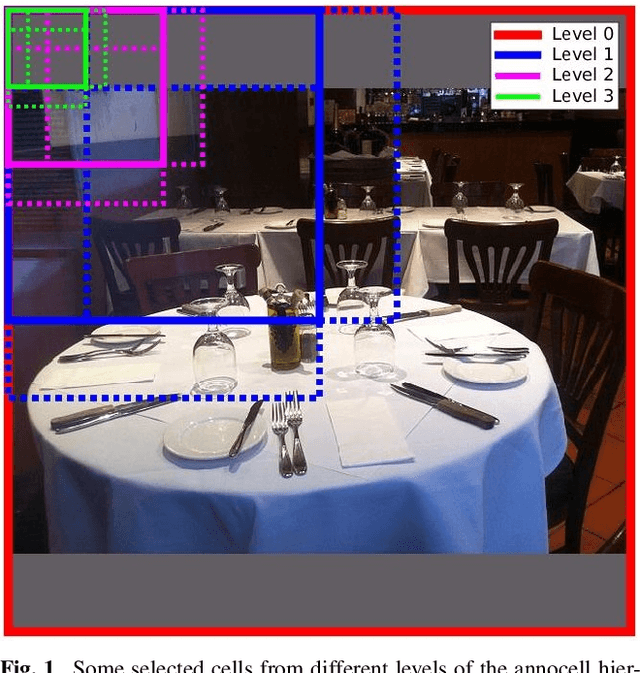
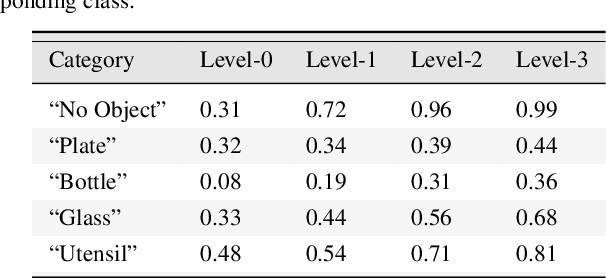

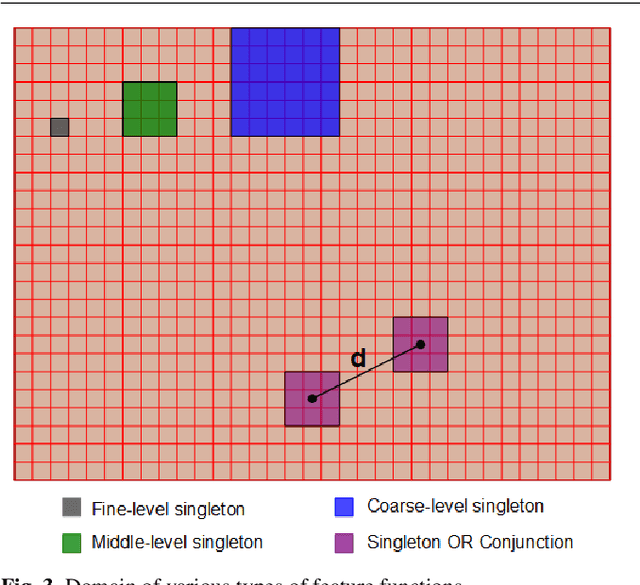
Despite enormous progress in object detection and classification, the problem of incorporating expected contextual relationships among object instances into modern recognition systems remains a key challenge. In this work we propose Information Pursuit, a Bayesian framework for scene parsing that combines prior models for the geometry of the scene and the spatial arrangement of objects instances with a data model for the output of high-level image classifiers trained to answer specific questions about the scene. In the proposed framework, the scene interpretation is progressively refined as evidence accumulates from the answers to a sequence of questions. At each step, we choose the question to maximize the mutual information between the new answer and the full interpretation given the current evidence obtained from previous inquiries. We also propose a method for learning the parameters of the model from synthesized, annotated scenes obtained by top-down sampling from an easy-to-learn generative scene model. Finally, we introduce a database of annotated indoor scenes of dining room tables, which we use to evaluate the proposed approach.