 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman Action Attribute Learning From Video Data Using Low-Rank Representations
Paper and Code
Dec 23, 2016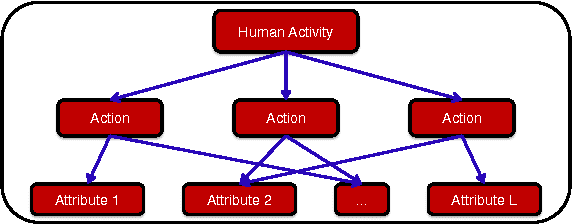
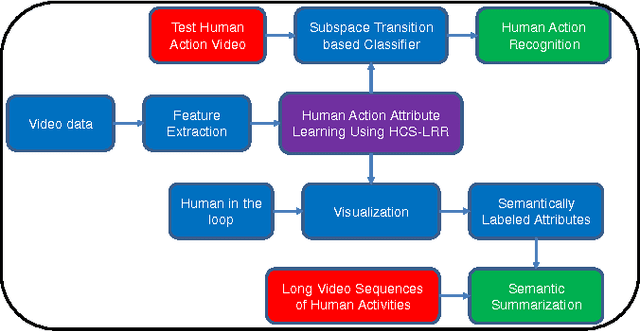
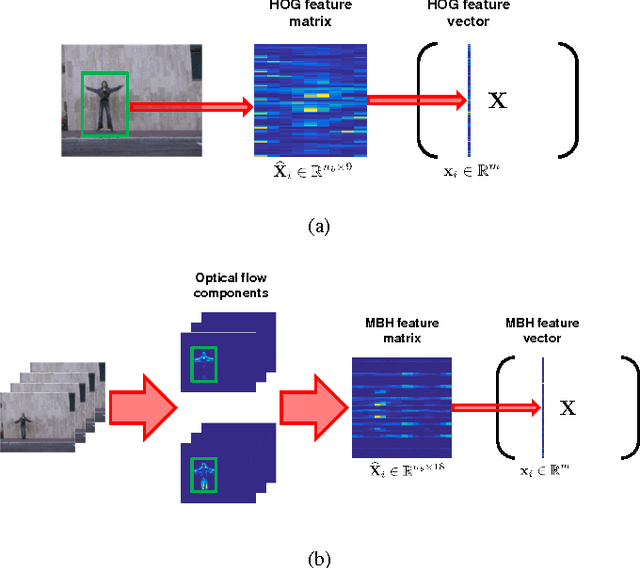

Representation of human actions as a sequence of human body movements or action attributes enables the development of models for human activity recognition and summarization. We present an extension of the low-rank representation (LRR) model, termed the clustering-aware structure-constrained low-rank representation (CS-LRR) model, for unsupervised learning of human action attributes from video data. Our model is based on the union-of-subspaces (UoS) framework, and integrates spectral clustering into the LRR optimization problem for better subspace clustering results. We lay out an efficient linear alternating direction method to solve the CS-LRR optimization problem. We also introduce a hierarchical subspace clustering approach, termed hierarchical CS-LRR, to learn the attributes without the need for a priori specification of their number. By visualizing and labeling these action attributes, the hierarchical model can be used to semantically summarize long video sequences of human actions at multiple resolutions. A human action or activity can also be uniquely represented as a sequence of transitions from one action attribute to another, which can then be used for human action recognition. We demonstrate the effectiveness of the proposed model for semantic summarization and action recognition through comprehensive experiments on five real-world human action datasets.