 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Motion Patterns in Videos
Paper and Code
Apr 10, 2017
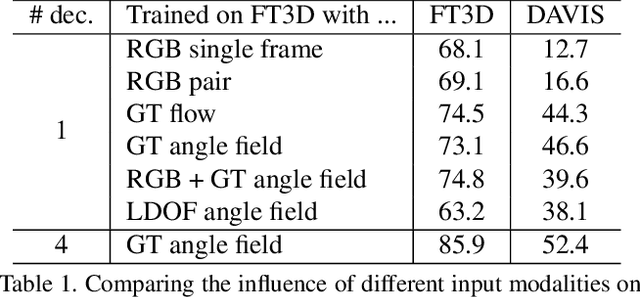

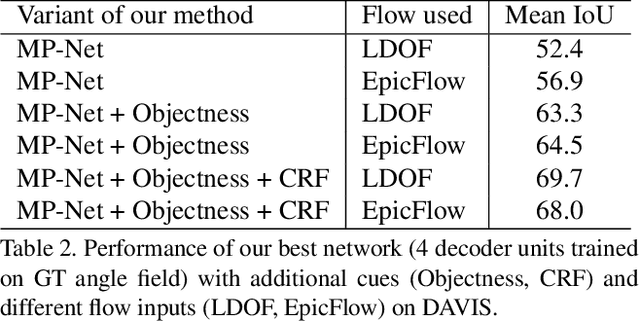
The problem of determining whether an object is in motion, irrespective of camera motion, is far from being solved. We address this challenging task by learning motion patterns in videos. The core of our approach is a fully convolutional network, which is learned entirely from synthetic video sequences, and their ground-truth optical flow and motion segmentation. This encoder-decoder style architecture first learns a coarse representation of the optical flow field features, and then refines it iteratively to produce motion labels at the original high-resolution. We further improve this labeling with an objectness map and a conditional random field, to account for errors in optical flow, and also to focus on moving "things" rather than "stuff". The output label of each pixel denotes whether it has undergone independent motion, i.e., irrespective of camera motion. We demonstrate the benefits of this learning framework on the moving object segmentation task, where the goal is to segment all objects in motion. Our approach outperforms the top method on the recently released DAVIS benchmark dataset, comprising real-world sequences, by 5.6%. We also evaluate on the Berkeley motion segmentation database, achieving state-of-the-art results.