 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction-Driven Object Detection with Top-Down Visual Attentions
Paper and Code


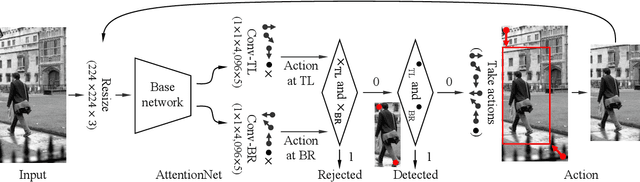
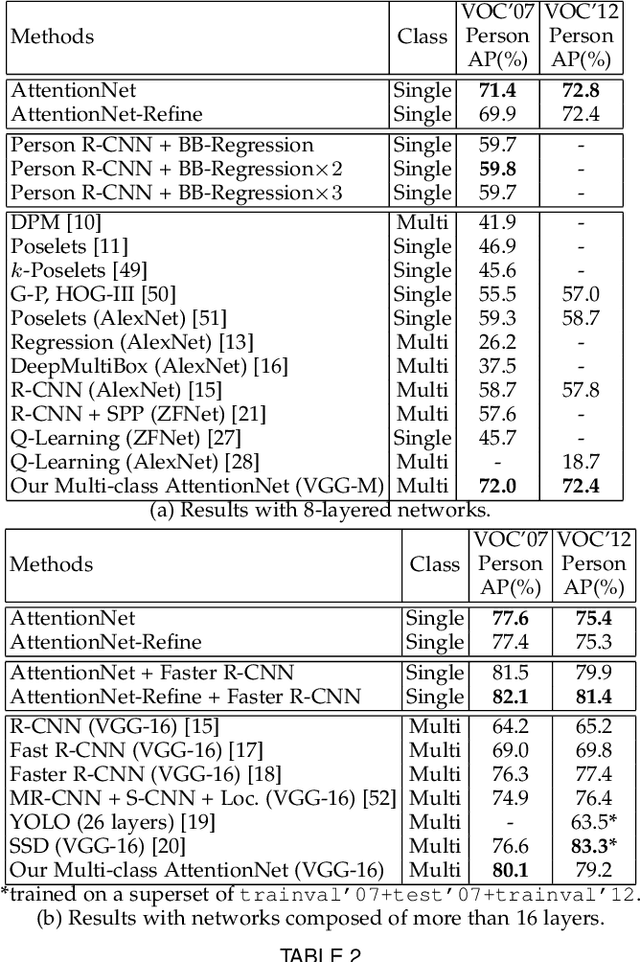
A dominant paradigm for deep learning based object detection relies on a "bottom-up" approach using "passive" scoring of class agnostic proposals. These approaches are efficient but lack of holistic analysis of scene-level context. In this paper, we present an "action-driven" detection mechanism using our "top-down" visual attention model. We localize an object by taking sequential actions that the attention model provides. The attention model conditioned with an image region provides required actions to get closer toward a target object. An action at each time step is weak itself but an ensemble of the sequential actions makes a bounding-box accurately converge to a target object boundary. This attention model we call AttentionNet is composed of a convolutional neural network. During our whole detection procedure, we only utilize the actions from a single AttentionNet without any modules for object proposals nor post bounding-box regression. We evaluate our top-down detection mechanism over the PASCAL VOC series and ILSVRC CLS-LOC dataset, and achieve state-of-the-art performances compared to the major bottom-up detection methods. In particular, our detection mechanism shows a strong advantage in elaborate localization by outperforming Faster R-CNN with a margin of +7.1% over PASCAL VOC 2007 when we increase the IoU threshold for positive detection to 0.7.