 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle Image Action Recognition using Semantic Body Part Actions
Paper and Code
Dec 14, 2016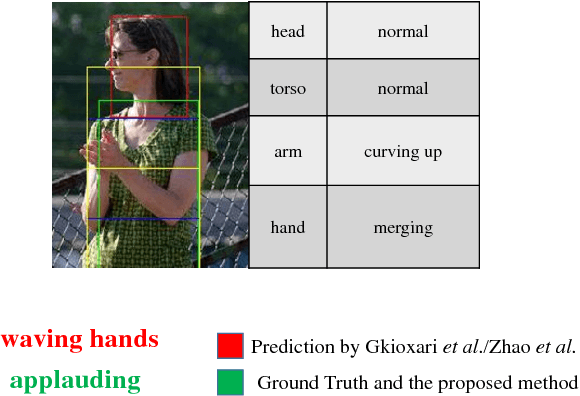
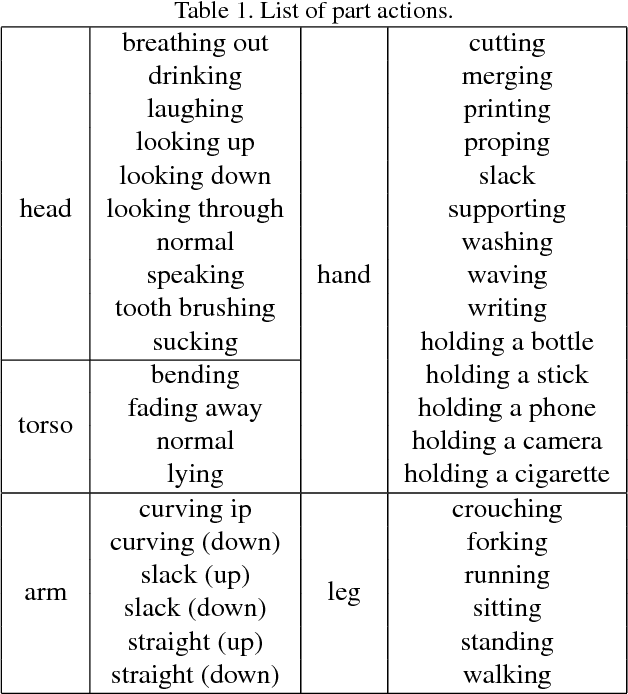
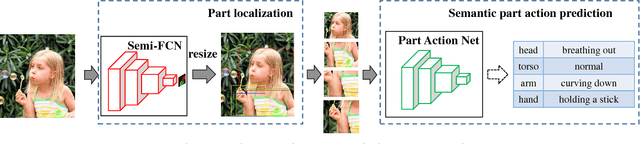
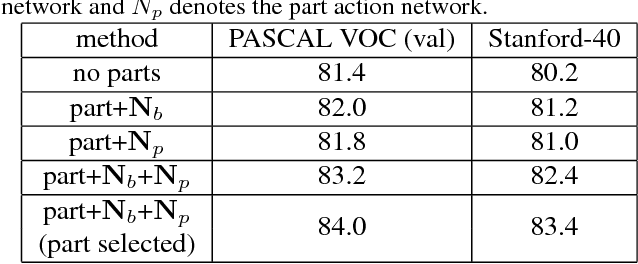
In this paper, we propose a novel single image action recognition algorithm which is based on the idea of semantic body part actions. Unlike existing bottom up methods, we argue that the human action is a combination of meaningful body part actions. In detail, we divide human body into five parts: head, torso, arms, hands and legs. And for each of the body parts, we define several semantic body part actions, e.g., hand holding, hand waving. These semantic body part actions are strongly related to the body actions, e.g., writing, and jogging. Based on the idea, we propose a deep neural network based system: first, body parts are localized by a Semi-FCN network. Second, for each body parts, a Part Action Res-Net is used to predict semantic body part actions. And finally, we use SVM to fuse the body part actions and predict the entire body action. Experiments on two dataset: PASCAL VOC 2012 and Stanford-40 report mAP improvement from the state-of-the-art by 3.8% and 2.6% respectively.