 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGesture-based Bootstrapping for Egocentric Hand Segmentation
Paper and Code
Jun 11, 2018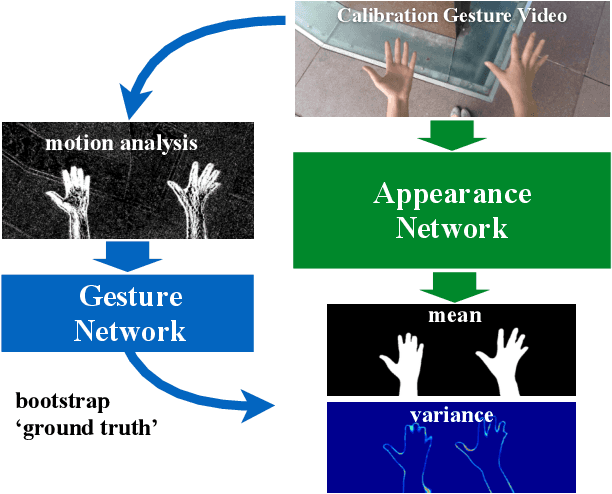
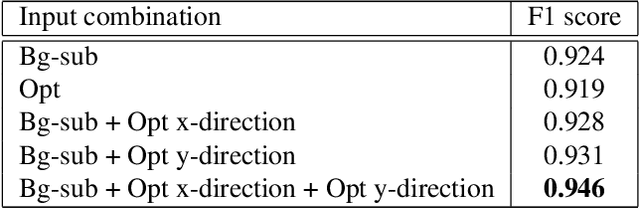

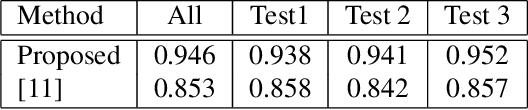
Accurately identifying hands in images is a key sub-task for human activity understanding with wearable first-person point-of-view cameras. Traditional hand segmentation approaches rely on a large corpus of manually labeled data to generate robust hand detectors. However, these approaches still face challenges as the appearance of the hand varies greatly across users, tasks, environments or illumination conditions. A key observation in the case of many wearable applications and interfaces is that, it is only necessary to accurately detect the user's hands in a specific situational context. Based on this observation, we introduce an interactive approach to learn a person-specific hand segmentation model that does not require any manually labeled training data. Our approach proceeds in two steps, an interactive bootstrapping step for identifying moving hand regions, followed by learning a personalized user specific hand appearance model. Concretely, our approach uses two convolutional neural networks: (1) a gesture network that uses pre-defined motion information to detect the hand region; and (2) an appearance network that learns a person specific model of the hand region based on the output of the gesture network. During training, to make the appearance network robust to errors in the gesture network, the loss function of the former network incorporates the confidence of the gesture network while learning. Experiments demonstrate the robustness of our approach with an F1 score over 0.8 on all challenging datasets across a wide range of illumination and hand appearance variations, improving over a baseline approach by over 10%.