 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Adversary-Resistant Deep Neural Networks
Paper and Code
Aug 19, 2017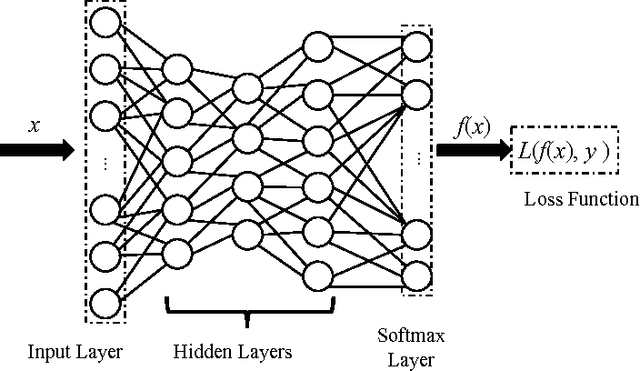
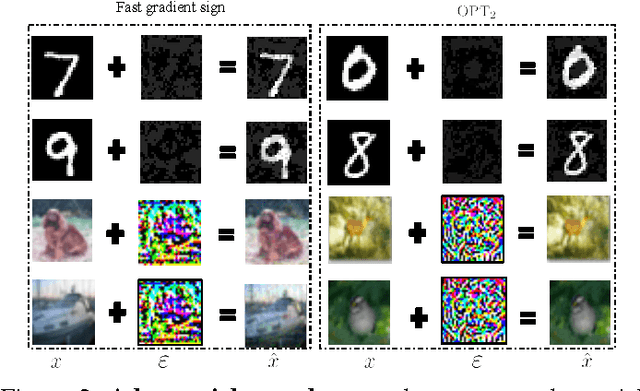
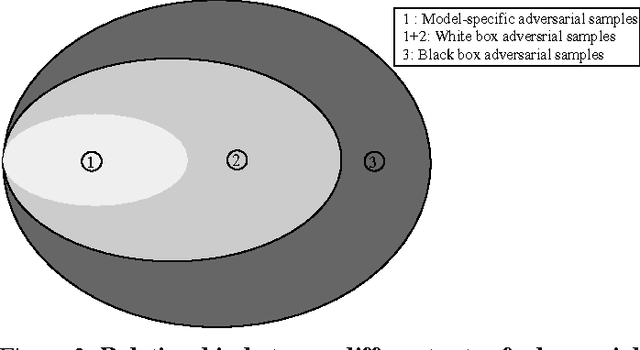
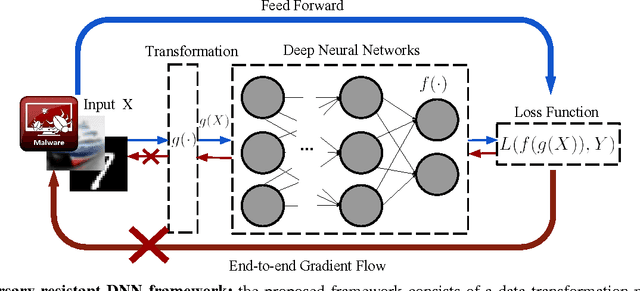
Deep neural networks (DNNs) have proven to be quite effective in a vast array of machine learning tasks, with recent examples in cyber security and autonomous vehicles. Despite the superior performance of DNNs in these applications, it has been recently shown that these models are susceptible to a particular type of attack that exploits a fundamental flaw in their design. This attack consists of generating particular synthetic examples referred to as adversarial samples. These samples are constructed by slightly manipulating real data-points in order to "fool" the original DNN model, forcing it to mis-classify previously correctly classified samples with high confidence. Addressing this flaw in the model is essential if DNNs are to be used in critical applications such as those in cyber security. Previous work has provided various learning algorithms to enhance the robustness of DNN models, and they all fall into the tactic of "security through obscurity". This means security can be guaranteed only if one can obscure the learning algorithms from adversaries. Once the learning technique is disclosed, DNNs protected by these defense mechanisms are still susceptible to adversarial samples. In this work, we investigate this issue shared across previous research work and propose a generic approach to escalate a DNN's resistance to adversarial samples. More specifically, our approach integrates a data transformation module with a DNN, making it robust even if we reveal the underlying learning algorithm. To demonstrate the generality of our proposed approach and its potential for handling cyber security applications, we evaluate our method and several other existing solutions on datasets publicly available. Our results indicate that our approach typically provides superior classification performance and resistance in comparison with state-of-art solutions.