 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Quantization: Encoding Convolutional Activations with Deep Generative Model
Paper and Code
Nov 29, 2016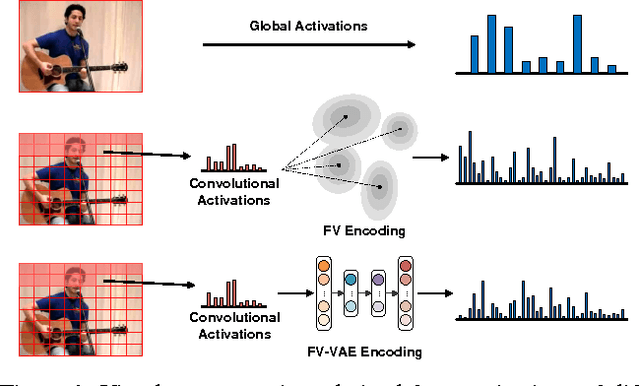
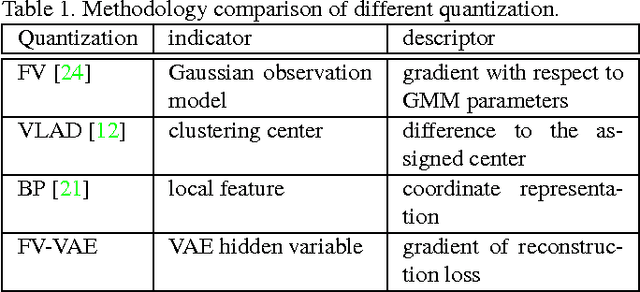
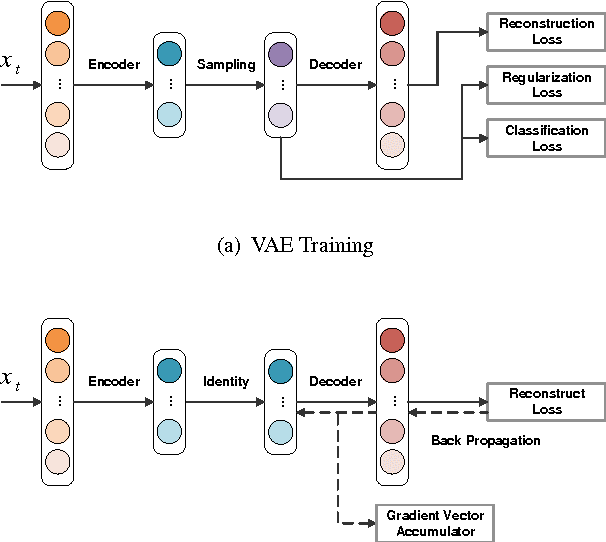
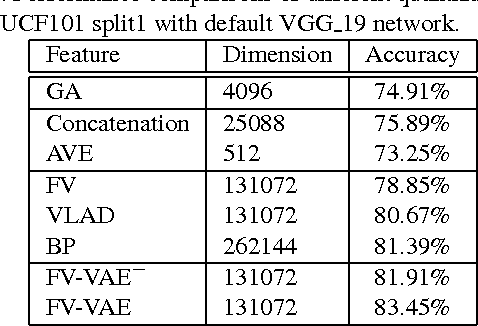
Deep convolutional neural networks (CNNs) have proven highly effective for visual recognition, where learning a universal representation from activations of convolutional layer plays a fundamental problem. In this paper, we present Fisher Vector encoding with Variational Auto-Encoder (FV-VAE), a novel deep architecture that quantizes the local activations of convolutional layer in a deep generative model, by training them in an end-to-end manner. To incorporate FV encoding strategy into deep generative models, we introduce Variational Auto-Encoder model, which steers a variational inference and learning in a neural network which can be straightforwardly optimized using standard stochastic gradient method. Different from the FV characterized by conventional generative models (e.g., Gaussian Mixture Model) which parsimoniously fit a discrete mixture model to data distribution, the proposed FV-VAE is more flexible to represent the natural property of data for better generalization. Extensive experiments are conducted on three public datasets, i.e., UCF101, ActivityNet, and CUB-200-2011 in the context of video action recognition and fine-grained image classification, respectively. Superior results are reported when compared to state-of-the-art representations. Most remarkably, our proposed FV-VAE achieves to-date the best published accuracy of 94.2% on UCF101.