 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Video Deblurring
Paper and Code

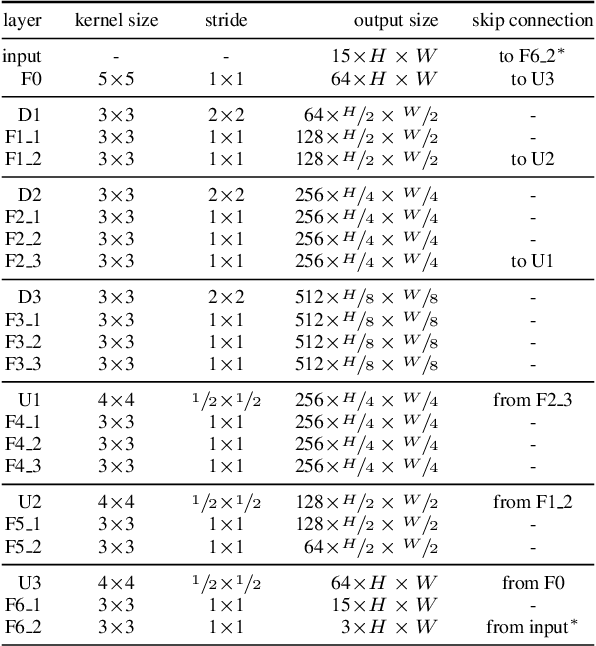
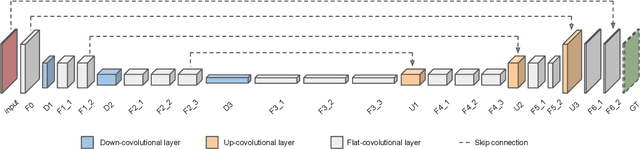

Motion blur from camera shake is a major problem in videos captured by hand-held devices. Unlike single-image deblurring, video-based approaches can take advantage of the abundant information that exists across neighboring frames. As a result the best performing methods rely on aligning nearby frames. However, aligning images is a computationally expensive and fragile procedure, and methods that aggregate information must therefore be able to identify which regions have been accurately aligned and which have not, a task which requires high level scene understanding. In this work, we introduce a deep learning solution to video deblurring, where a CNN is trained end-to-end to learn how to accumulate information across frames. To train this network, we collected a dataset of real videos recorded with a high framerate camera, which we use to generate synthetic motion blur for supervision. We show that the features learned from this dataset extend to deblurring motion blur that arises due to camera shake in a wide range of videos, and compare the quality of results to a number of other baselines.