 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA dataset and exploration of models for understanding video data through fill-in-the-blank question-answering
Paper and Code

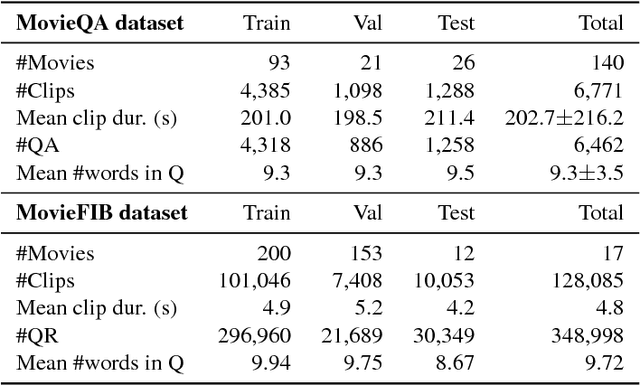
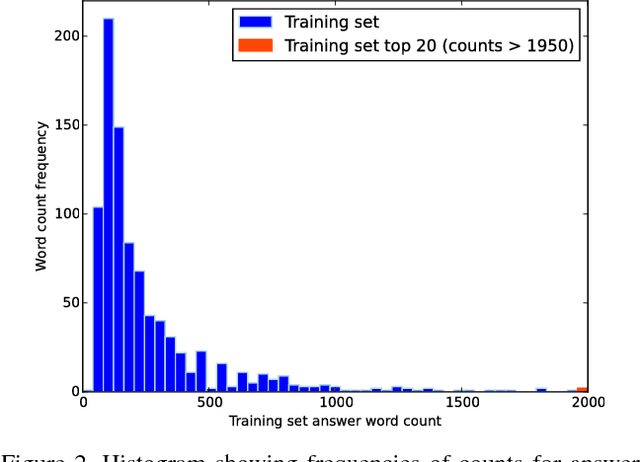
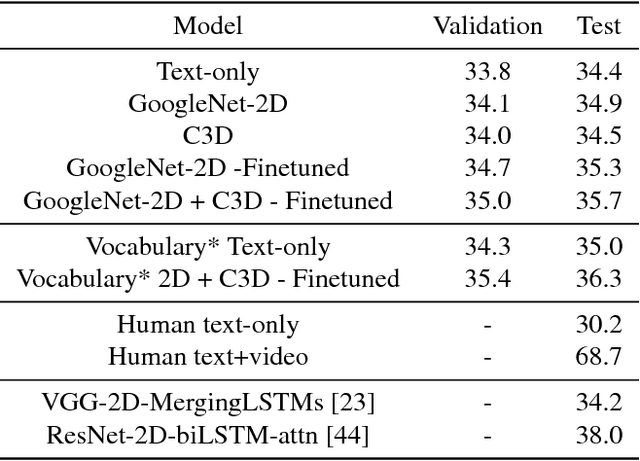
While deep convolutional neural networks frequently approach or exceed human-level performance at benchmark tasks involving static images, extending this success to moving images is not straightforward. Having models which can learn to understand video is of interest for many applications, including content recommendation, prediction, summarization, event/object detection and understanding human visual perception, but many domains lack sufficient data to explore and perfect video models. In order to address the need for a simple, quantitative benchmark for developing and understanding video, we present MovieFIB, a fill-in-the-blank question-answering dataset with over 300,000 examples, based on descriptive video annotations for the visually impaired. In addition to presenting statistics and a description of the dataset, we perform a detailed analysis of 5 different models' predictions, and compare these with human performance. We investigate the relative importance of language, static (2D) visual features, and moving (3D) visual features; the effects of increasing dataset size, the number of frames sampled; and of vocabulary size. We illustrate that: this task is not solvable by a language model alone; our model combining 2D and 3D visual information indeed provides the best result; all models perform significantly worse than human-level. We provide human evaluations for responses given by different models and find that accuracy on the MovieFIB evaluation corresponds well with human judgement. We suggest avenues for improving video models, and hope that the proposed dataset can be useful for measuring and encouraging progress in this very interesting field.