 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to scale distributed deep learning?
Paper and Code
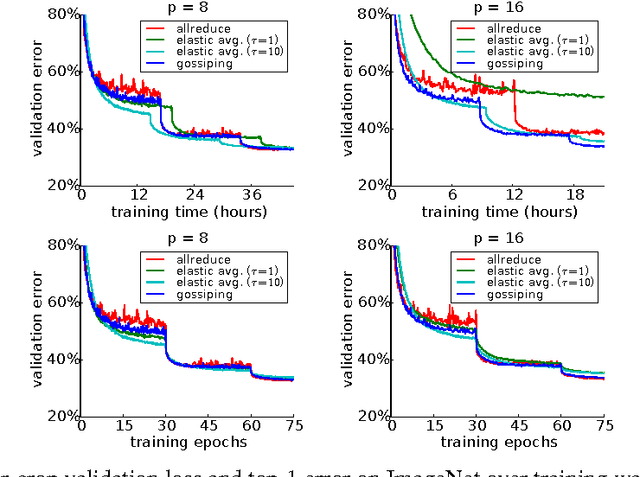
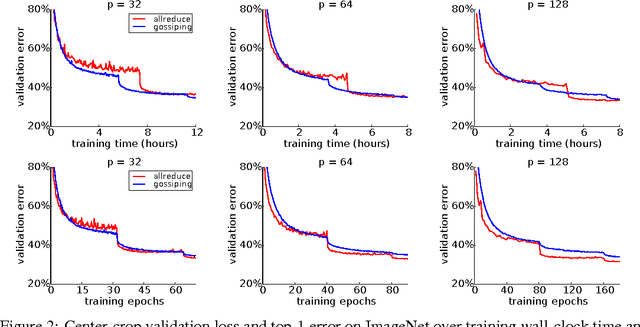
Training time on large datasets for deep neural networks is the principal workflow bottleneck in a number of important applications of deep learning, such as object classification and detection in automatic driver assistance systems (ADAS). To minimize training time, the training of a deep neural network must be scaled beyond a single machine to as many machines as possible by distributing the optimization method used for training. While a number of approaches have been proposed for distributed stochastic gradient descent (SGD), at the current time synchronous approaches to distributed SGD appear to be showing the greatest performance at large scale. Synchronous scaling of SGD suffers from the need to synchronize all processors on each gradient step and is not resilient in the face of failing or lagging processors. In asynchronous approaches using parameter servers, training is slowed by contention to the parameter server. In this paper we compare the convergence of synchronous and asynchronous SGD for training a modern ResNet network architecture on the ImageNet classification problem. We also propose an asynchronous method, gossiping SGD, that aims to retain the positive features of both systems by replacing the all-reduce collective operation of synchronous training with a gossip aggregation algorithm. We find, perhaps counterintuitively, that asynchronous SGD, including both elastic averaging and gossiping, converges faster at fewer nodes (up to about 32 nodes), whereas synchronous SGD scales better to more nodes (up to about 100 nodes).