 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Taylor Approximations: Convergence and Exploration in Rectifier Networks
Paper and Code
Jun 06, 2018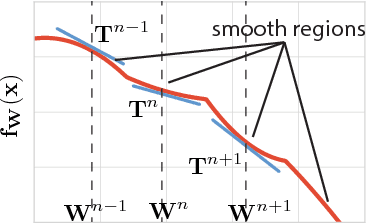
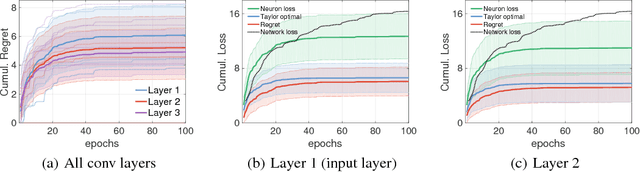
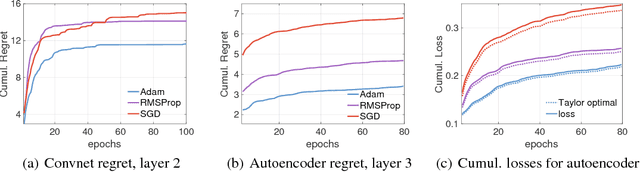
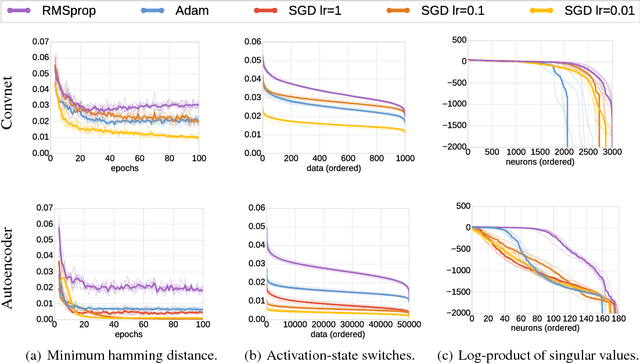
Modern convolutional networks, incorporating rectifiers and max-pooling, are neither smooth nor convex; standard guarantees therefore do not apply. Nevertheless, methods from convex optimization such as gradient descent and Adam are widely used as building blocks for deep learning algorithms. This paper provides the first convergence guarantee applicable to modern convnets, which furthermore matches a lower bound for convex nonsmooth functions. The key technical tool is the neural Taylor approximation -- a straightforward application of Taylor expansions to neural networks -- and the associated Taylor loss. Experiments on a range of optimizers, layers, and tasks provide evidence that the analysis accurately captures the dynamics of neural optimization. The second half of the paper applies the Taylor approximation to isolate the main difficulty in training rectifier nets -- that gradients are shattered -- and investigates the hypothesis that, by exploring the space of activation configurations more thoroughly, adaptive optimizers such as RMSProp and Adam are able to converge to better solutions.