 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQ-Prop: Sample-Efficient Policy Gradient with An Off-Policy Critic
Paper and Code

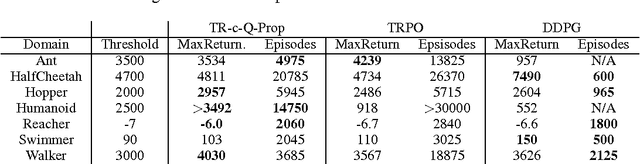
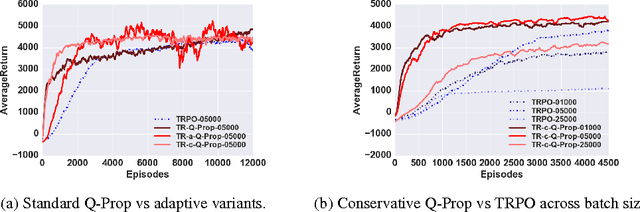

Model-free deep reinforcement learning (RL) methods have been successful in a wide variety of simulated domains. However, a major obstacle facing deep RL in the real world is their high sample complexity. Batch policy gradient methods offer stable learning, but at the cost of high variance, which often requires large batches. TD-style methods, such as off-policy actor-critic and Q-learning, are more sample-efficient but biased, and often require costly hyperparameter sweeps to stabilize. In this work, we aim to develop methods that combine the stability of policy gradients with the efficiency of off-policy RL. We present Q-Prop, a policy gradient method that uses a Taylor expansion of the off-policy critic as a control variate. Q-Prop is both sample efficient and stable, and effectively combines the benefits of on-policy and off-policy methods. We analyze the connection between Q-Prop and existing model-free algorithms, and use control variate theory to derive two variants of Q-Prop with conservative and aggressive adaptation. We show that conservative Q-Prop provides substantial gains in sample efficiency over trust region policy optimization (TRPO) with generalized advantage estimation (GAE), and improves stability over deep deterministic policy gradient (DDPG), the state-of-the-art on-policy and off-policy methods, on OpenAI Gym's MuJoCo continuous control environments.