 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtein Secondary Structure Prediction Using Deep Multi-scale Convolutional Neural Networks and Next-Step Conditioning
Paper and Code
Nov 04, 2016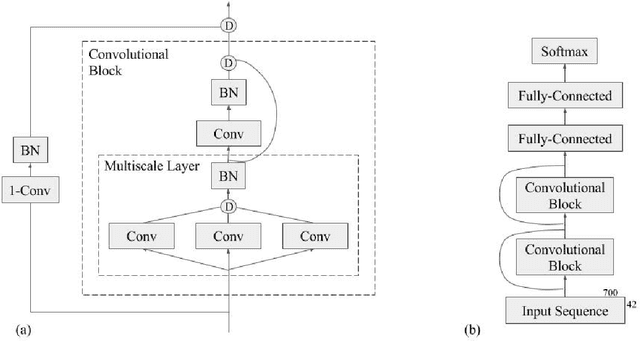
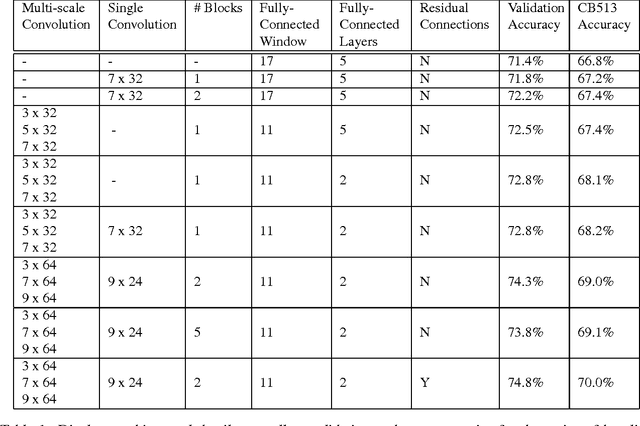
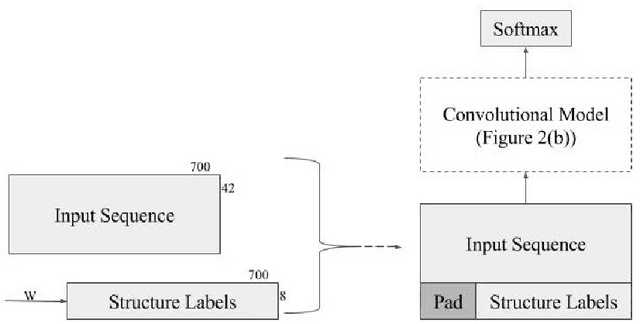
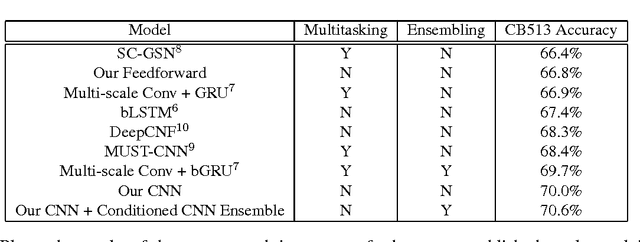
Recently developed deep learning techniques have significantly improved the accuracy of various speech and image recognition systems. In this paper we adapt some of these techniques for protein secondary structure prediction. We first train a series of deep neural networks to predict eight-class secondary structure labels given a protein's amino acid sequence information and find that using recent methods for regularization, such as dropout and weight-norm constraining, leads to measurable gains in accuracy. We then adapt recent convolutional neural network architectures--Inception, ReSNet, and DenseNet with Batch Normalization--to the problem of protein structure prediction. These convolutional architectures make heavy use of multi-scale filter layers that simultaneously compute features on several scales, and use residual connections to prevent underfitting. Using a carefully modified version of these architectures, we achieve state-of-the-art performance of 70.0% per amino acid accuracy on the public CB513 benchmark dataset. Finally, we explore additions from sequence-to-sequence learning, altering the model to make its predictions conditioned on both the protein's amino acid sequence and its past secondary structure labels. We introduce a new method of ensembling such a conditional model with our convolutional model, an approach which reaches 70.6% Q8 accuracy on CB513. We argue that these results can be further refined for larger boosts in prediction accuracy through more sophisticated attempts to control overfitting of conditional models. We aim to release the code for these experiments as part of the TensorFlow repository.