 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomatic Identification of Sarcasm Target: An Introductory Approach
Paper and Code
Aug 25, 2017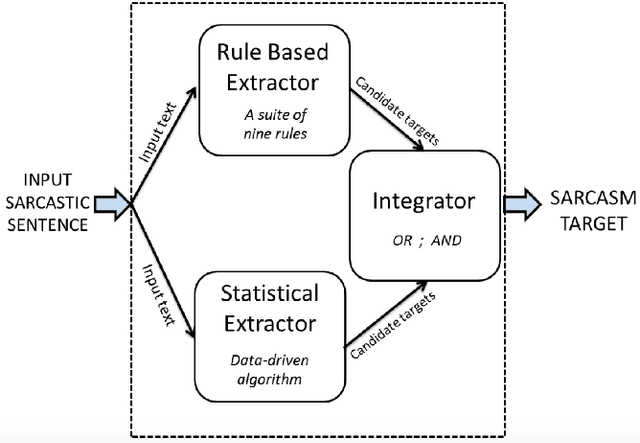



Past work in computational sarcasm deals primarily with sarcasm detection. In this paper, we introduce a novel, related problem: sarcasm target identification i.e., extracting the target of ridicule in a sarcastic sentence). We present an introductory approach for sarcasm target identification. Our approach employs two types of extractors: one based on rules, and another consisting of a statistical classifier. To compare our approach, we use two baselines: a na\"ive baseline and another baseline based on work in sentiment target identification. We perform our experiments on book snippets and tweets, and show that our hybrid approach performs better than the two baselines and also, in comparison with using the two extractors individually. Our introductory approach establishes the viability of sarcasm target identification, and will serve as a baseline for future work.