 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmall-footprint Highway Deep Neural Networks for Speech Recognition
Paper and Code
Apr 25, 2017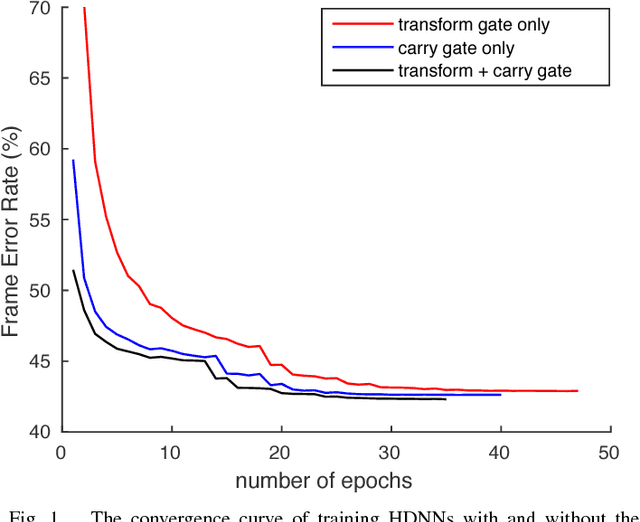
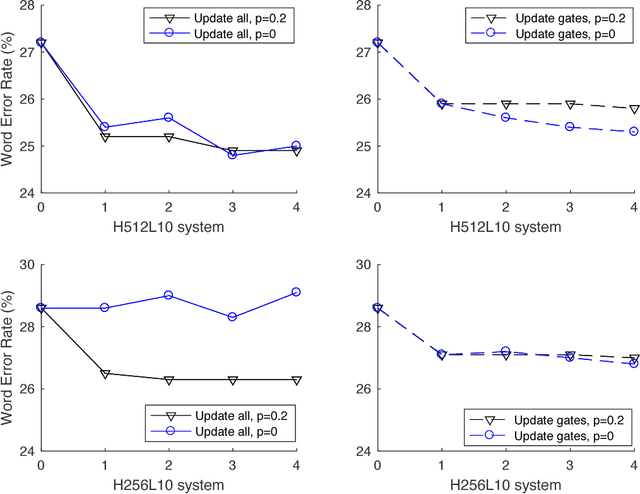
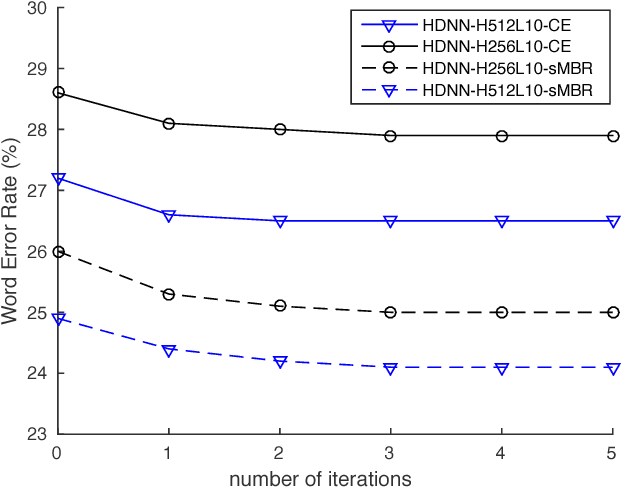
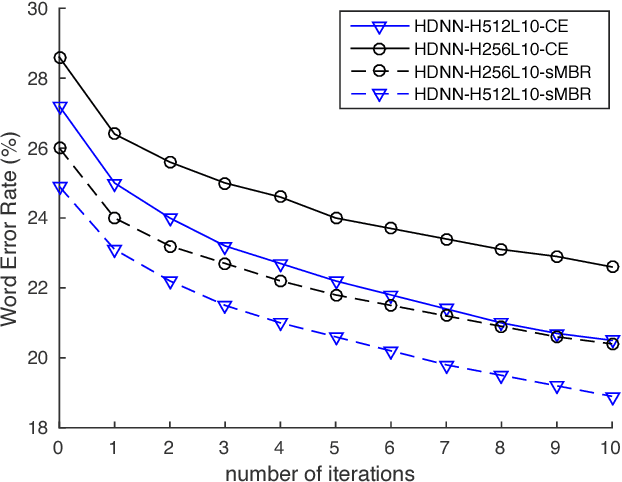
State-of-the-art speech recognition systems typically employ neural network acoustic models. However, compared to Gaussian mixture models, deep neural network (DNN) based acoustic models often have many more model parameters, making it challenging for them to be deployed on resource-constrained platforms, such as mobile devices. In this paper, we study the application of the recently proposed highway deep neural network (HDNN) for training small-footprint acoustic models. HDNNs are a depth-gated feedforward neural network, which include two types of gate functions to facilitate the information flow through different layers. Our study demonstrates that HDNNs are more compact than regular DNNs for acoustic modeling, i.e., they can achieve comparable recognition accuracy with many fewer model parameters. Furthermore, HDNNs are more controllable than DNNs: the gate functions of an HDNN can control the behavior of the whole network using a very small number of model parameters. Finally, we show that HDNNs are more adaptable than DNNs. For example, simply updating the gate functions using adaptation data can result in considerable gains in accuracy. We demonstrate these aspects by experiments using the publicly available AMI corpus, which has around 80 hours of training data.