 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversary Resistant Deep Neural Networks with an Application to Malware Detection
Paper and Code
Apr 27, 2017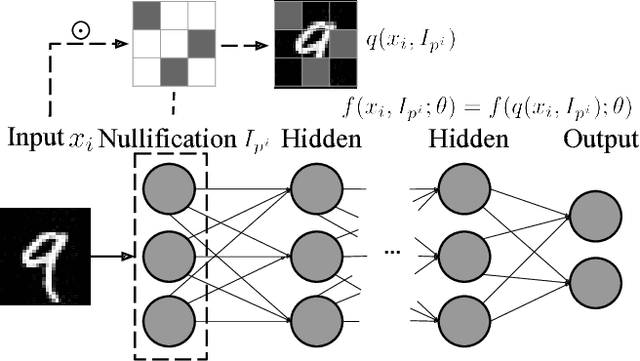

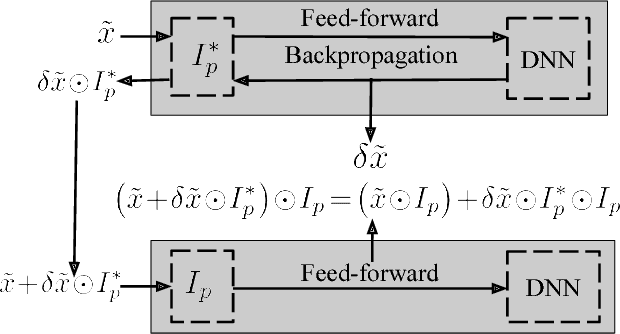
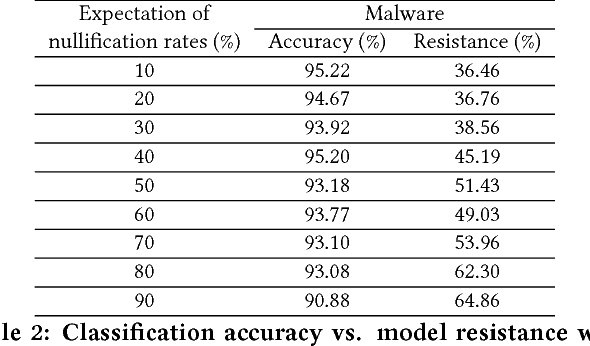
Beyond its highly publicized victories in Go, there have been numerous successful applications of deep learning in information retrieval, computer vision and speech recognition. In cybersecurity, an increasing number of companies have become excited about the potential of deep learning, and have started to use it for various security incidents, the most popular being malware detection. These companies assert that deep learning (DL) could help turn the tide in the battle against malware infections. However, deep neural networks (DNNs) are vulnerable to adversarial samples, a flaw that plagues most if not all statistical learning models. Recent research has demonstrated that those with malicious intent can easily circumvent deep learning-powered malware detection by exploiting this flaw. In order to address this problem, previous work has developed various defense mechanisms that either augmenting training data or enhance model's complexity. However, after a thorough analysis of the fundamental flaw in DNNs, we discover that the effectiveness of current defenses is limited and, more importantly, cannot provide theoretical guarantees as to their robustness against adversarial sampled-based attacks. As such, we propose a new adversary resistant technique that obstructs attackers from constructing impactful adversarial samples by randomly nullifying features within samples. In this work, we evaluate our proposed technique against a real world dataset with 14,679 malware variants and 17,399 benign programs. We theoretically validate the robustness of our technique, and empirically show that our technique significantly boosts DNN robustness to adversarial samples while maintaining high accuracy in classification. To demonstrate the general applicability of our proposed method, we also conduct experiments using the MNIST and CIFAR-10 datasets, generally used in image recognition research.