 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulticlass Classification Calibration Functions
Paper and Code
Sep 20, 2016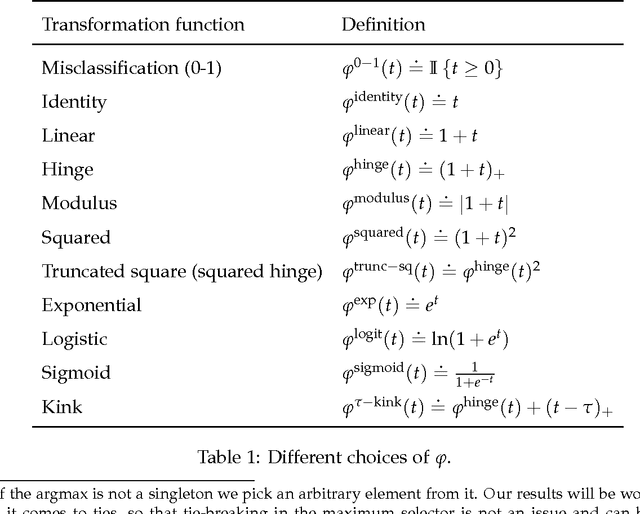



In this paper we refine the process of computing calibration functions for a number of multiclass classification surrogate losses. Calibration functions are a powerful tool for easily converting bounds for the surrogate risk (which can be computed through well-known methods) into bounds for the true risk, the probability of making a mistake. They are particularly suitable in non-parametric settings, where the approximation error can be controlled, and provide tighter bounds than the common technique of upper-bounding the 0-1 loss by the surrogate loss. The abstract nature of the more sophisticated existing calibration function results requires calibration functions to be explicitly derived on a case-by-case basis, requiring repeated efforts whenever bounds for a new surrogate loss are required. We devise a streamlined analysis that simplifies the process of deriving calibration functions for a large number of surrogate losses that have been proposed in the literature. The effort of deriving calibration functions is then surmised in verifying, for a chosen surrogate loss, a small number of conditions that we introduce. As case studies, we recover existing calibration functions for the well-known loss of Lee et al. (2004), and also provide novel calibration functions for well-known losses, including the one-versus-all loss and the logistic regression loss, plus a number of other losses that have been shown to be classification-calibrated in the past, but for which no calibration function had been derived.