 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatio-temporal Aware Non-negative Component Representation for Action Recognition
Paper and Code
Aug 27, 2016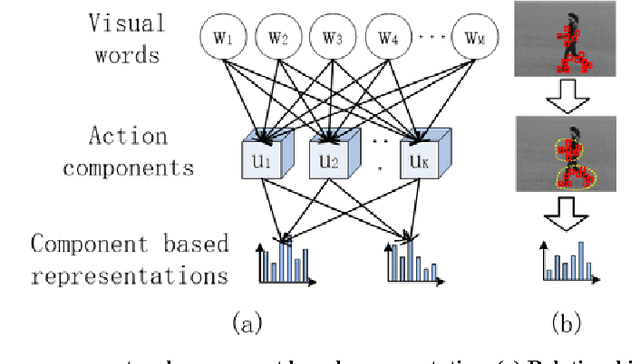
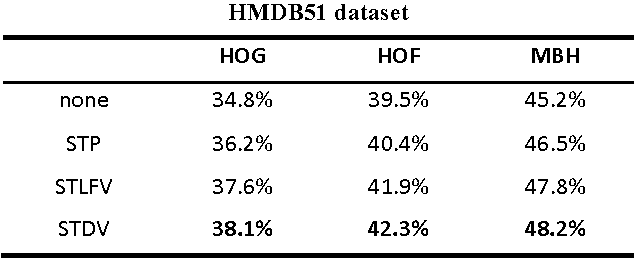
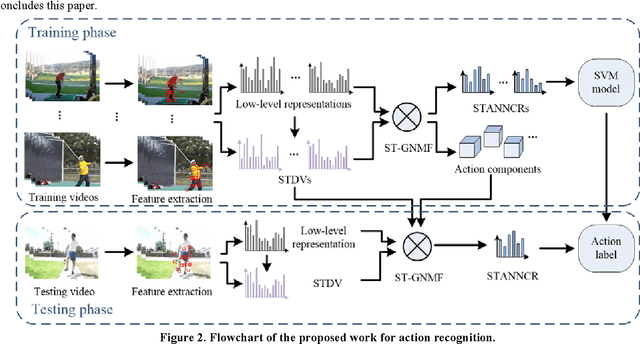
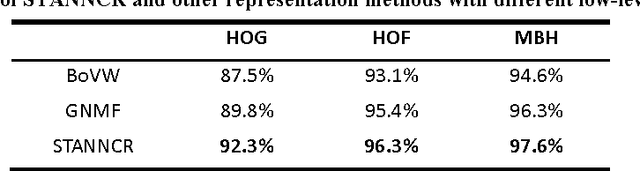
This paper presents a novel mid-level representation for action recognition, named spatio-temporal aware non-negative component representation (STANNCR). The proposed STANNCR is based on action component and incorporates the spatial-temporal information. We first introduce a spatial-temporal distribution vector (STDV) to model the distributions of local feature locations in a compact and discriminative manner. Then we employ non-negative matrix factorization (NMF) to learn the action components and encode the video samples. The action component considers the correlations of visual words, which effectively bridge the sematic gap in action recognition. To incorporate the spatial-temporal cues for final representation, the STDV is used as the part of graph regularization for NMF. The fusion of spatial-temporal information makes the STANNCR more discriminative, and our fusion manner is more compact than traditional method of concatenating vectors. The proposed approach is extensively evaluated on three public datasets. The experimental results demonstrate the effectiveness of STANNCR for action recognition.