 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Shallow High-Order Parametric Approach to Data Visualization and Compression
Paper and Code
Aug 16, 2016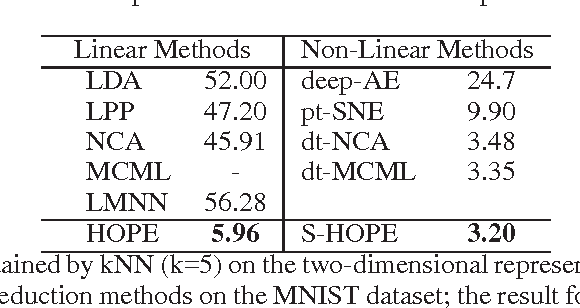


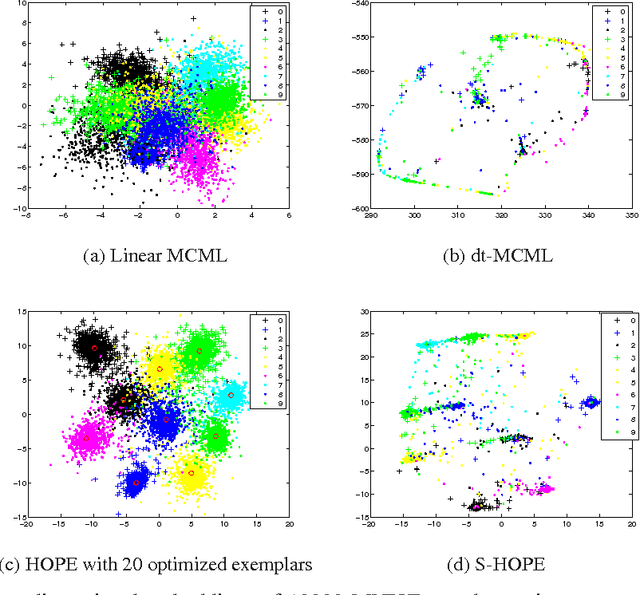
Explicit high-order feature interactions efficiently capture essential structural knowledge about the data of interest and have been used for constructing generative models. We present a supervised discriminative High-Order Parametric Embedding (HOPE) approach to data visualization and compression. Compared to deep embedding models with complicated deep architectures, HOPE generates more effective high-order feature mapping through an embarrassingly simple shallow model. Furthermore, two approaches to generating a small number of exemplars conveying high-order interactions to represent large-scale data sets are proposed. These exemplars in combination with the feature mapping learned by HOPE effectively capture essential data variations. Moreover, through HOPE, these exemplars are employed to increase the computational efficiency of kNN classification for fast information retrieval by thousands of times. For classification in two-dimensional embedding space on MNIST and USPS datasets, our shallow method HOPE with simple Sigmoid transformations significantly outperforms state-of-the-art supervised deep embedding models based on deep neural networks, and even achieved historically low test error rate of 0.65% in two-dimensional space on MNIST, which demonstrates the representational efficiency and power of supervised shallow models with high-order feature interactions.