 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Hashing: A Joint Approach for Image Signature Learning
Paper and Code
Aug 12, 2016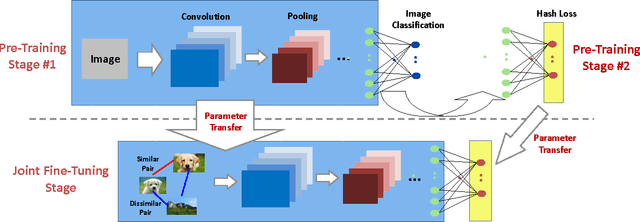
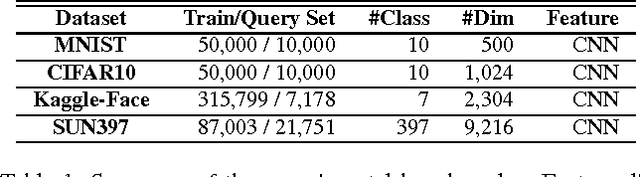

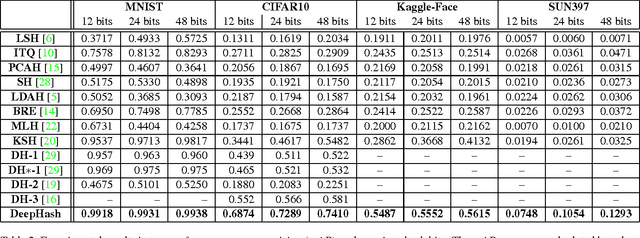
Similarity-based image hashing represents crucial technique for visual data storage reduction and expedited image search. Conventional hashing schemes typically feed hand-crafted features into hash functions, which separates the procedures of feature extraction and hash function learning. In this paper, we propose a novel algorithm that concurrently performs feature engineering and non-linear supervised hashing function learning. Our technical contributions in this paper are two-folds: 1) deep network optimization is often achieved by gradient propagation, which critically requires a smooth objective function. The discrete nature of hash codes makes them not amenable for gradient-based optimization. To address this issue, we propose an exponentiated hashing loss function and its bilinear smooth approximation. Effective gradient calculation and propagation are thereby enabled; 2) pre-training is an important trick in supervised deep learning. The impact of pre-training on the hash code quality has never been discussed in current deep hashing literature. We propose a pre-training scheme inspired by recent advance in deep network based image classification, and experimentally demonstrate its effectiveness. Comprehensive quantitative evaluations are conducted on several widely-used image benchmarks. On all benchmarks, our proposed deep hashing algorithm outperforms all state-of-the-art competitors by significant margins. In particular, our algorithm achieves a near-perfect 0.99 in terms of Hamming ranking accuracy with only 12 bits on MNIST, and a new record of 0.74 on the CIFAR10 dataset. In comparison, the best accuracies obtained on CIFAR10 by existing hashing algorithms without or with deep networks are known to be 0.36 and 0.58 respectively.