 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNovel Word Embedding and Translation-based Language Modeling for Extractive Speech Summarization
Paper and Code
Jul 22, 2016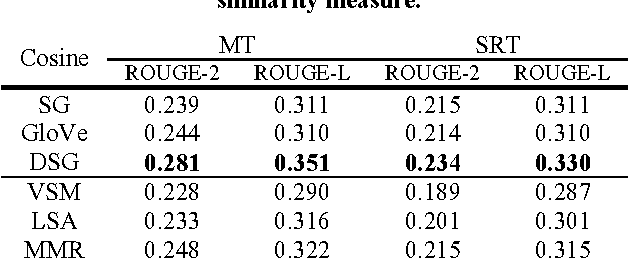


Word embedding methods revolve around learning continuous distributed vector representations of words with neural networks, which can capture semantic and/or syntactic cues, and in turn be used to induce similarity measures among words, sentences and documents in context. Celebrated methods can be categorized as prediction-based and count-based methods according to the training objectives and model architectures. Their pros and cons have been extensively analyzed and evaluated in recent studies, but there is relatively less work continuing the line of research to develop an enhanced learning method that brings together the advantages of the two model families. In addition, the interpretation of the learned word representations still remains somewhat opaque. Motivated by the observations and considering the pressing need, this paper presents a novel method for learning the word representations, which not only inherits the advantages of classic word embedding methods but also offers a clearer and more rigorous interpretation of the learned word representations. Built upon the proposed word embedding method, we further formulate a translation-based language modeling framework for the extractive speech summarization task. A series of empirical evaluations demonstrate the effectiveness of the proposed word representation learning and language modeling techniques in extractive speech summarization.