 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient differentially private learning improves drug sensitivity prediction
Paper and Code
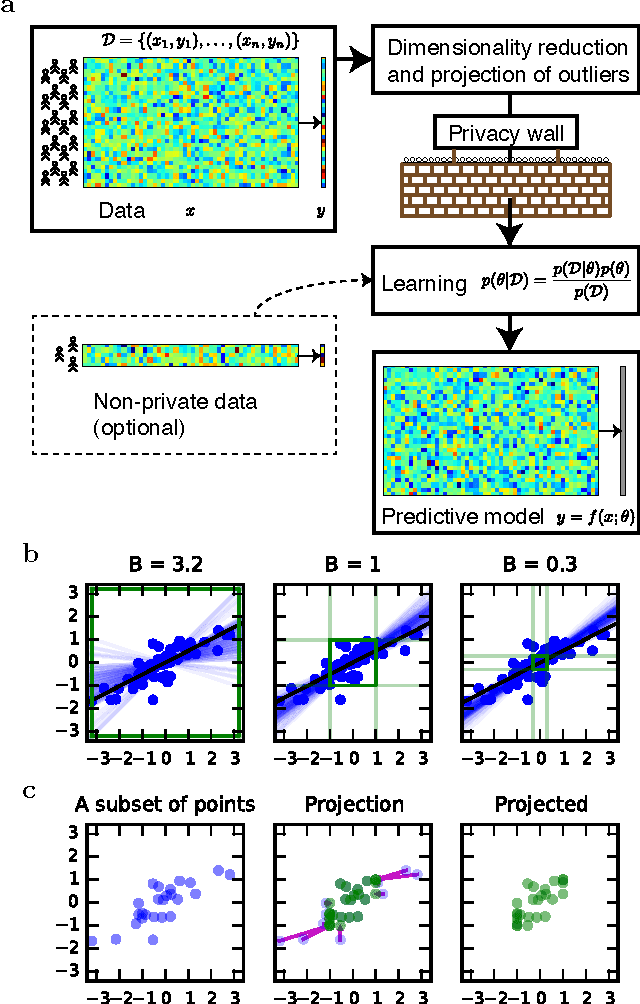
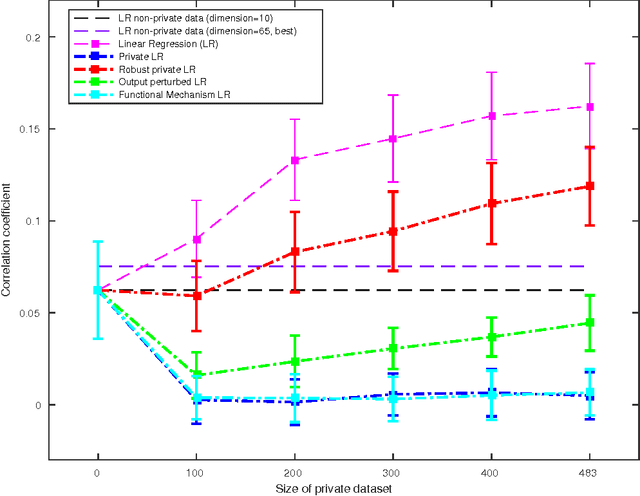
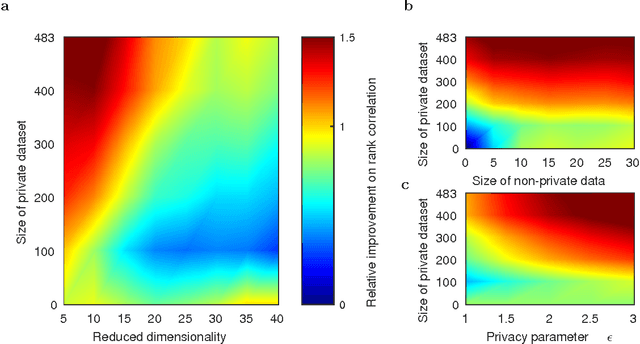
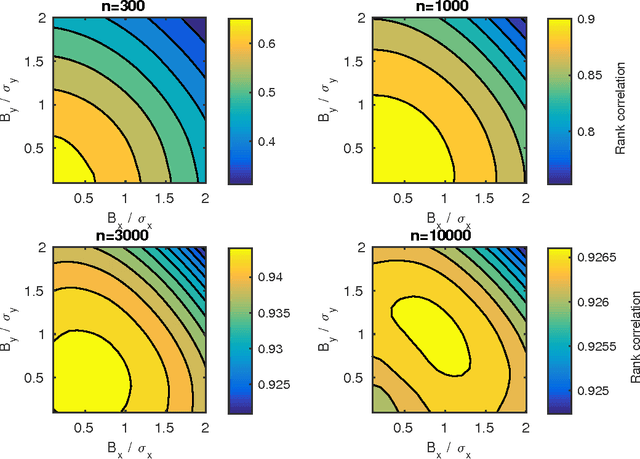
Users of a personalised recommendation system face a dilemma: recommendations can be improved by learning from data, but only if the other users are willing to share their private information. Good personalised predictions are vitally important in precision medicine, but genomic information on which the predictions are based is also particularly sensitive, as it directly identifies the patients and hence cannot easily be anonymised. Differential privacy has emerged as a potentially promising solution: privacy is considered sufficient if presence of individual patients cannot be distinguished. However, differentially private learning with current methods does not improve predictions with feasible data sizes and dimensionalities. Here we show that useful predictors can be learned under powerful differential privacy guarantees, and even from moderately-sized data sets, by demonstrating significant improvements with a new robust private regression method in the accuracy of private drug sensitivity prediction. The method combines two key properties not present even in recent proposals, which can be generalised to other predictors: we prove it is asymptotically consistently and efficiently private, and demonstrate that it performs well on finite data. Good finite data performance is achieved by limiting the sharing of private information by decreasing the dimensionality and by projecting outliers to fit tighter bounds, therefore needing to add less noise for equal privacy. As already the simple-to-implement method shows promise on the challenging genomic data, we anticipate rapid progress towards practical applications in many fields, such as mobile sensing and social media, in addition to the badly needed precision medicine solutions.