 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Pricing with Demand Covariates
Paper and Code
Apr 25, 2016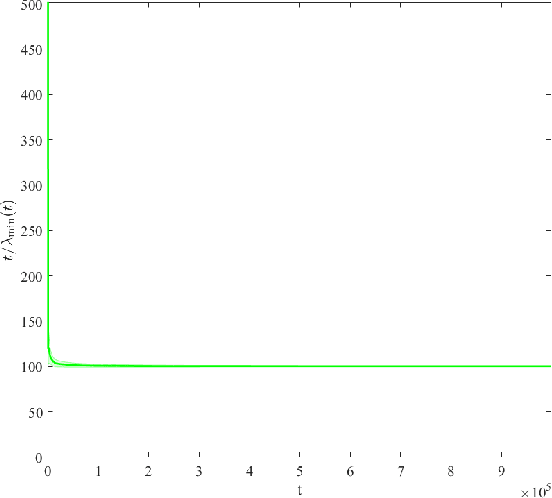
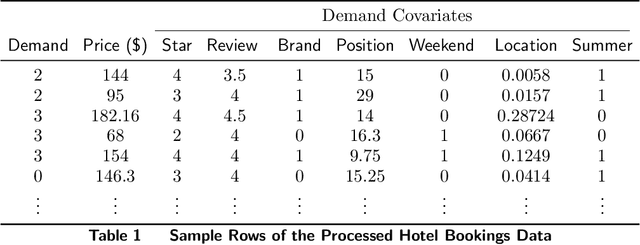
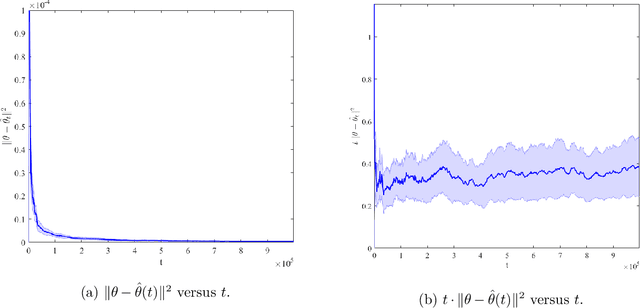
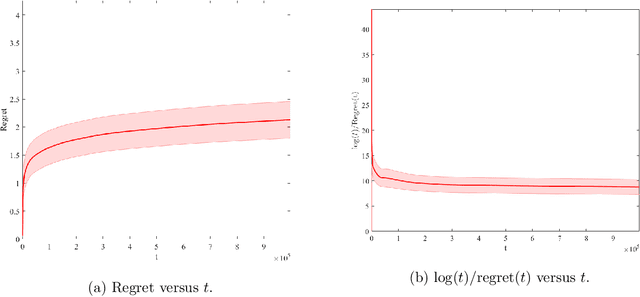
We consider a firm that sells products over $T$ periods without knowing the demand function. The firm sequentially sets prices to earn revenue and to learn the underlying demand function simultaneously. A natural heuristic for this problem, commonly used in practice, is greedy iterative least squares (GILS). At each time period, GILS estimates the demand as a linear function of the price by applying least squares to the set of prior prices and realized demands. Then a price that maximizes the revenue, given the estimated demand function, is used for the next time period. The performance is measured by the regret, which is the expected revenue loss from the optimal (oracle) pricing policy when the demand function is known. Recently, den Boer and Zwart (2014) and Keskin and Zeevi (2014) demonstrated that GILS is sub-optimal. They introduced algorithms which integrate forced price dispersion with GILS and achieve asymptotically optimal performance. In this paper, we consider this dynamic pricing problem in a data-rich environment. In particular, we assume that the firm knows the expected demand under a particular price from historical data, and in each period, before setting the price, the firm has access to extra information (demand covariates) which may be predictive of the demand. We prove that in this setting GILS achieves asymptotically optimal regret of order $\log(T)$. We also show the following surprising result: in the original dynamic pricing problem of den Boer and Zwart (2014) and Keskin and Zeevi (2014), inclusion of any set of covariates in GILS as potential demand covariates (even though they could carry no information) would make GILS asymptotically optimal. We validate our results via extensive numerical simulations on synthetic and real data sets.