 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat do different evaluation metrics tell us about saliency models?
Paper and Code
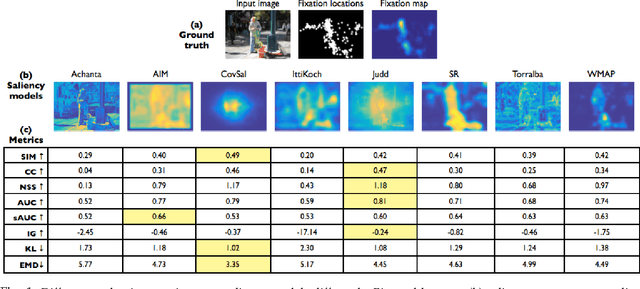

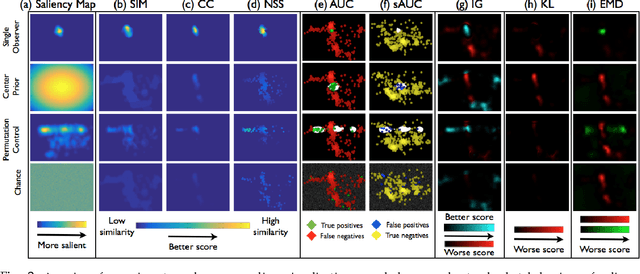
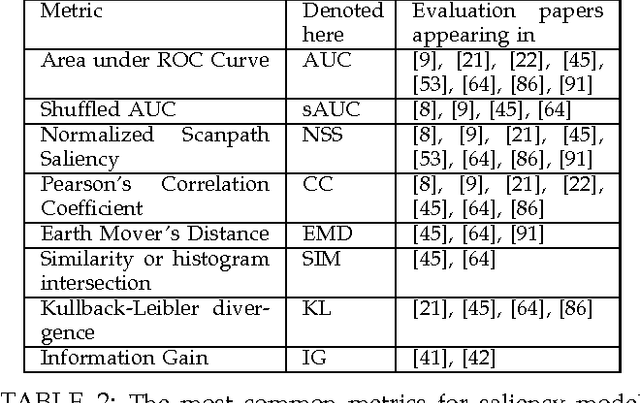
How best to evaluate a saliency model's ability to predict where humans look in images is an open research question. The choice of evaluation metric depends on how saliency is defined and how the ground truth is represented. Metrics differ in how they rank saliency models, and this results from how false positives and false negatives are treated, whether viewing biases are accounted for, whether spatial deviations are factored in, and how the saliency maps are pre-processed. In this paper, we provide an analysis of 8 different evaluation metrics and their properties. With the help of systematic experiments and visualizations of metric computations, we add interpretability to saliency scores and more transparency to the evaluation of saliency models. Building off the differences in metric properties and behaviors, we make recommendations for metric selections under specific assumptions and for specific applications.