 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDASA: Domain Adaptation in Stacked Autoencoders using Systematic Dropout
Paper and Code
Mar 19, 2016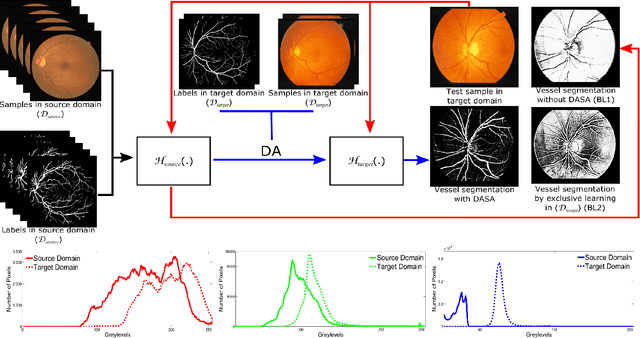
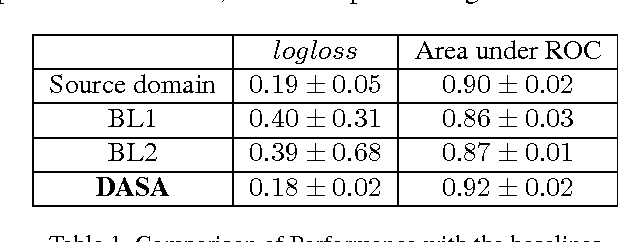
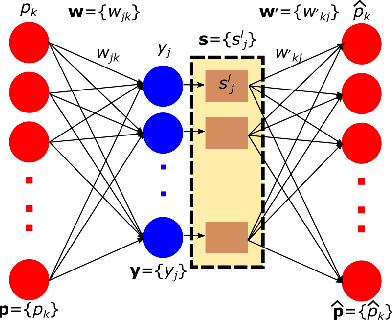
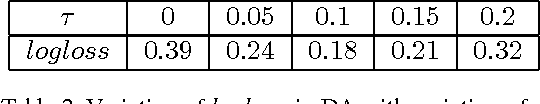
Domain adaptation deals with adapting behaviour of machine learning based systems trained using samples in source domain to their deployment in target domain where the statistics of samples in both domains are dissimilar. The task of directly training or adapting a learner in the target domain is challenged by lack of abundant labeled samples. In this paper we propose a technique for domain adaptation in stacked autoencoder (SAE) based deep neural networks (DNN) performed in two stages: (i) unsupervised weight adaptation using systematic dropouts in mini-batch training, (ii) supervised fine-tuning with limited number of labeled samples in target domain. We experimentally evaluate performance in the problem of retinal vessel segmentation where the SAE-DNN is trained using large number of labeled samples in the source domain (DRIVE dataset) and adapted using less number of labeled samples in target domain (STARE dataset). The performance of SAE-DNN measured using $logloss$ in source domain is $0.19$, without and with adaptation are $0.40$ and $0.18$, and $0.39$ when trained exclusively with limited samples in target domain. The area under ROC curve is observed respectively as $0.90$, $0.86$, $0.92$ and $0.87$. The high efficiency of vessel segmentation with DASA strongly substantiates our claim.