 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNormalization Propagation: A Parametric Technique for Removing Internal Covariate Shift in Deep Networks
Paper and Code
Jul 12, 2016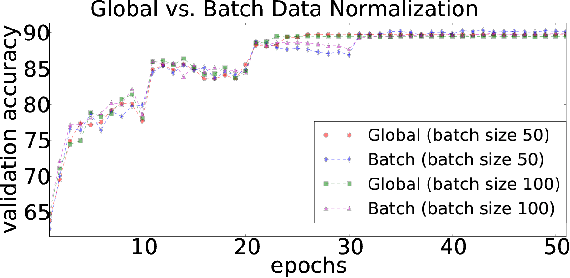
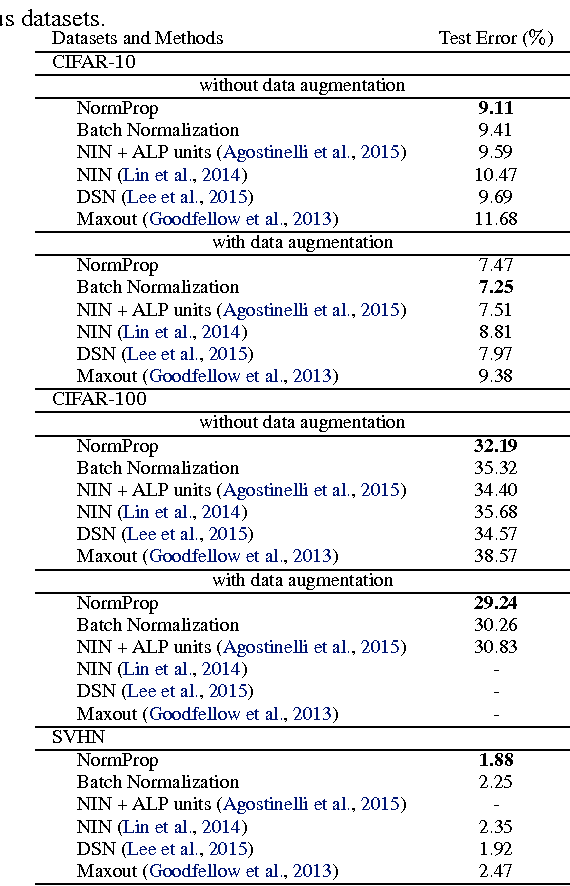

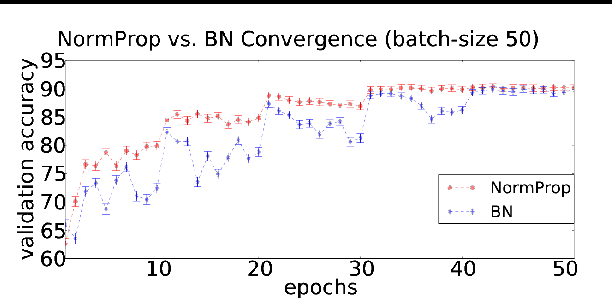
While the authors of Batch Normalization (BN) identify and address an important problem involved in training deep networks-- Internal Covariate Shift-- the current solution has certain drawbacks. Specifically, BN depends on batch statistics for layerwise input normalization during training which makes the estimates of mean and standard deviation of input (distribution) to hidden layers inaccurate for validation due to shifting parameter values (especially during initial training epochs). Also, BN cannot be used with batch-size 1 during training. We address these drawbacks by proposing a non-adaptive normalization technique for removing internal covariate shift, that we call Normalization Propagation. Our approach does not depend on batch statistics, but rather uses a data-independent parametric estimate of mean and standard-deviation in every layer thus being computationally faster compared with BN. We exploit the observation that the pre-activation before Rectified Linear Units follow Gaussian distribution in deep networks, and that once the first and second order statistics of any given dataset are normalized, we can forward propagate this normalization without the need for recalculating the approximate statistics for hidden layers.