 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat is the right way to represent document images?
Paper and Code
Dec 02, 2016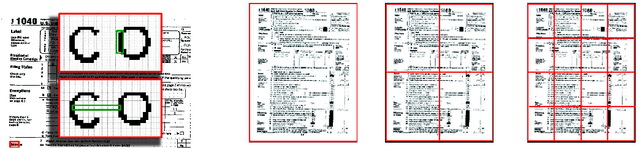
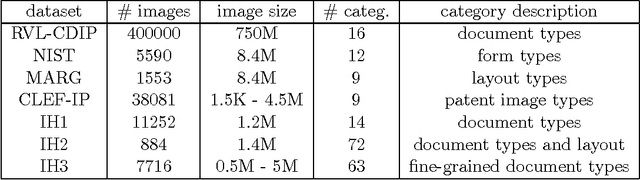
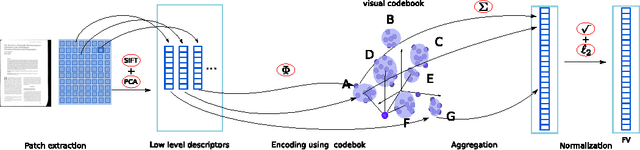

In this article we study the problem of document image representation based on visual features. We propose a comprehensive experimental study that compares three types of visual document image representations: (1) traditional so-called shallow features, such as the RunLength and the Fisher-Vector descriptors, (2) deep features based on Convolutional Neural Networks, and (3) features extracted from hybrid architectures that take inspiration from the two previous ones. We evaluate these features in several tasks (i.e. classification, clustering, and retrieval) and in different setups (e.g. domain transfer) using several public and in-house datasets. Our results show that deep features generally outperform other types of features when there is no domain shift and the new task is closely related to the one used to train the model. However, when a large domain or task shift is present, the Fisher-Vector shallow features generalize better and often obtain the best results.