 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextual LSTM models for Large scale NLP tasks
Paper and Code
May 31, 2016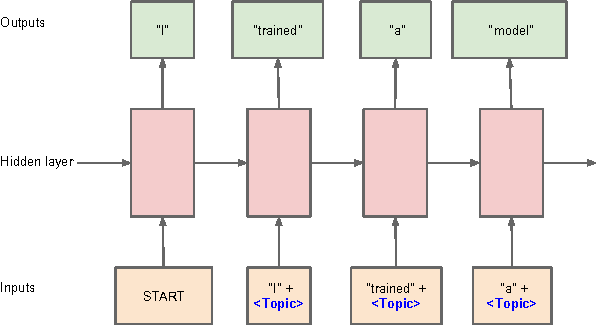
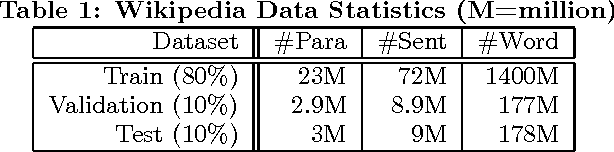
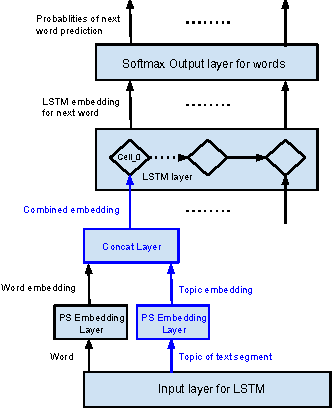
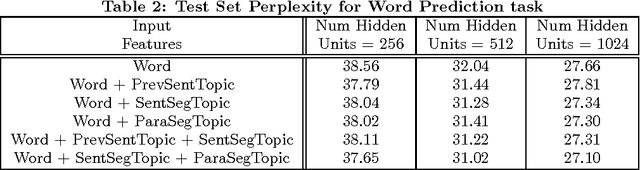
Documents exhibit sequential structure at multiple levels of abstraction (e.g., sentences, paragraphs, sections). These abstractions constitute a natural hierarchy for representing the context in which to infer the meaning of words and larger fragments of text. In this paper, we present CLSTM (Contextual LSTM), an extension of the recurrent neural network LSTM (Long-Short Term Memory) model, where we incorporate contextual features (e.g., topics) into the model. We evaluate CLSTM on three specific NLP tasks: word prediction, next sentence selection, and sentence topic prediction. Results from experiments run on two corpora, English documents in Wikipedia and a subset of articles from a recent snapshot of English Google News, indicate that using both words and topics as features improves performance of the CLSTM models over baseline LSTM models for these tasks. For example on the next sentence selection task, we get relative accuracy improvements of 21% for the Wikipedia dataset and 18% for the Google News dataset. This clearly demonstrates the significant benefit of using context appropriately in natural language (NL) tasks. This has implications for a wide variety of NL applications like question answering, sentence completion, paraphrase generation, and next utterance prediction in dialog systems.