Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNode-By-Node Greedy Deep Learning for Interpretable Features
Paper and Code
Feb 19, 2016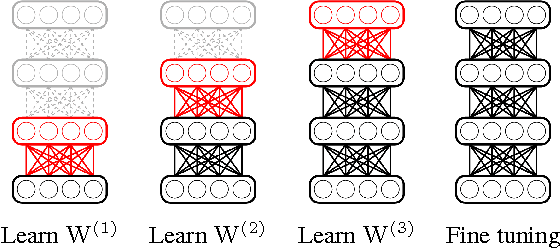
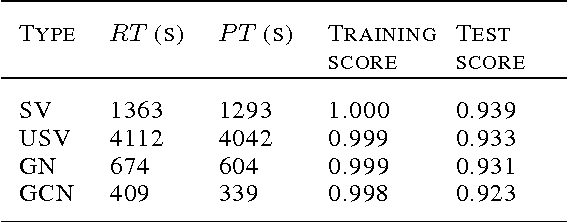

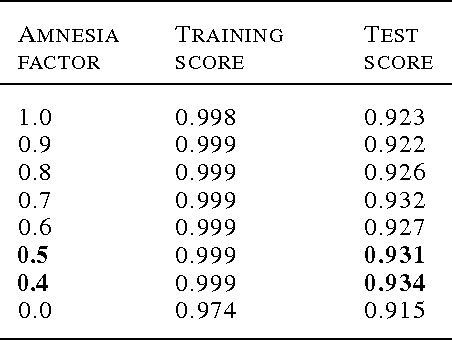
Multilayer networks have seen a resurgence under the umbrella of deep learning. Current deep learning algorithms train the layers of the network sequentially, improving algorithmic performance as well as providing some regularization. We present a new training algorithm for deep networks which trains \emph{each node in the network} sequentially. Our algorithm is orders of magnitude faster, creates more interpretable internal representations at the node level, while not sacrificing on the ultimate out-of-sample performance.
View paper on