 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData-Efficient Reinforcement Learning in Continuous-State POMDPs
Paper and Code
Feb 08, 2016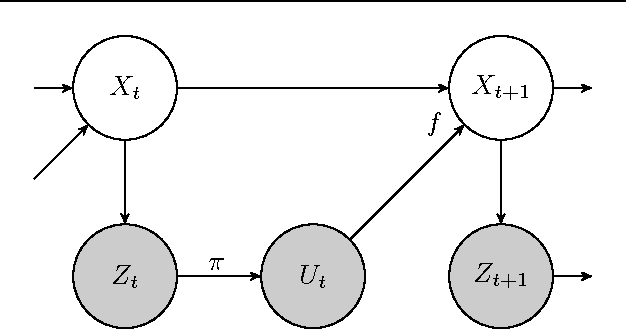
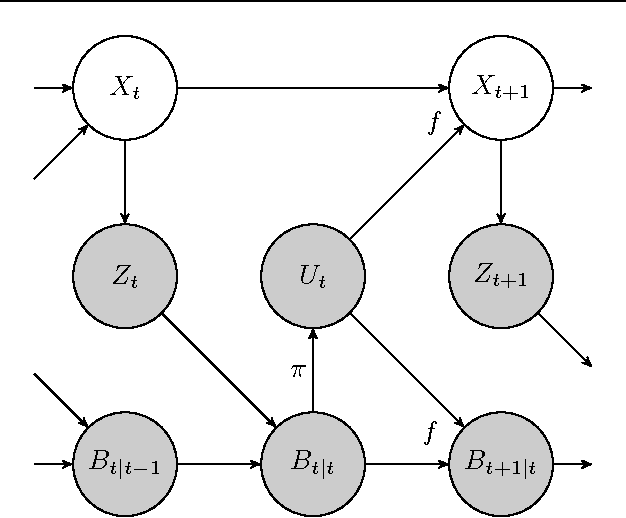
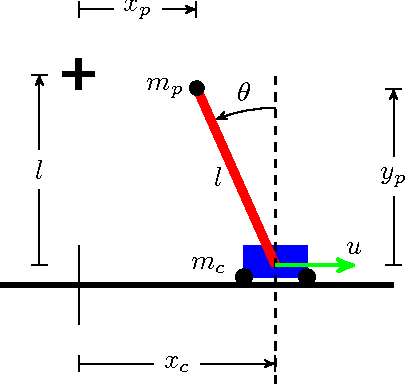
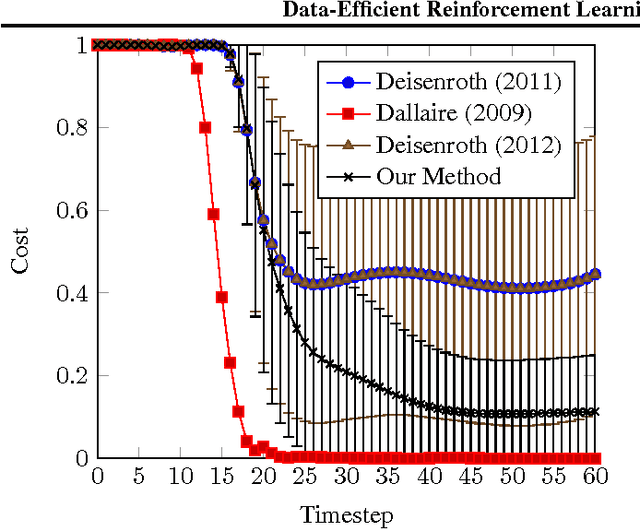
We present a data-efficient reinforcement learning algorithm resistant to observation noise. Our method extends the highly data-efficient PILCO algorithm (Deisenroth & Rasmussen, 2011) into partially observed Markov decision processes (POMDPs) by considering the filtering process during policy evaluation. PILCO conducts policy search, evaluating each policy by first predicting an analytic distribution of possible system trajectories. We additionally predict trajectories w.r.t. a filtering process, achieving significantly higher performance than combining a filter with a policy optimised by the original (unfiltered) framework. Our test setup is the cartpole swing-up task with sensor noise, which involves nonlinear dynamics and requires nonlinear control.