 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBinarized Neural Networks
Paper and Code
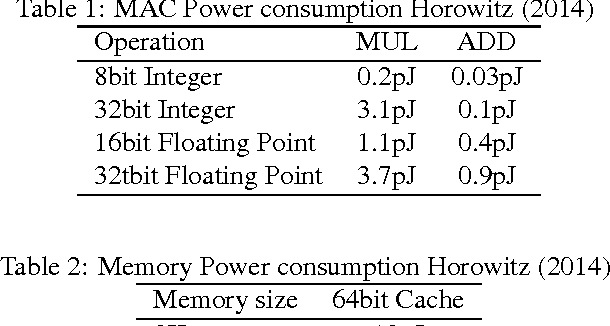
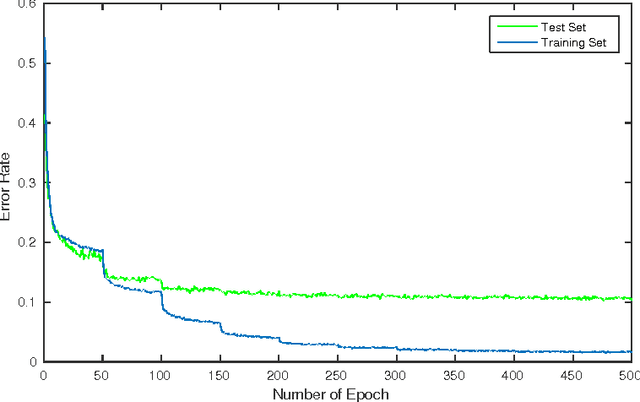

We introduce a method to train Binarized Neural Networks (BNNs) - neural networks with binary weights and activations at run-time and when computing the parameters' gradient at train-time. We conduct two sets of experiments, each based on a different framework, namely Torch7 and Theano, where we train BNNs on MNIST, CIFAR-10 and SVHN, and achieve nearly state-of-the-art results. During the forward pass, BNNs drastically reduce memory size and accesses, and replace most arithmetic operations with bit-wise operations, which might lead to a great increase in power-efficiency. Last but not least, we wrote a binary matrix multiplication GPU kernel with which it is possible to run our MNIST BNN 7 times faster than with an unoptimized GPU kernel, without suffering any loss in classification accuracy. The code for training and running our BNNs is available.