 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Deep Multi-View Representation Learning: Objectives and Optimization
Paper and Code
Feb 02, 2016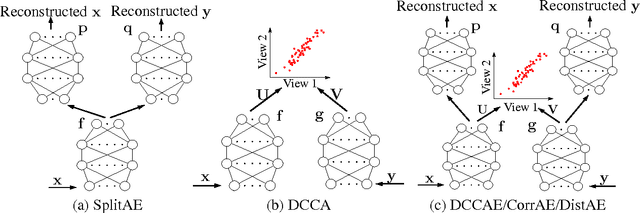
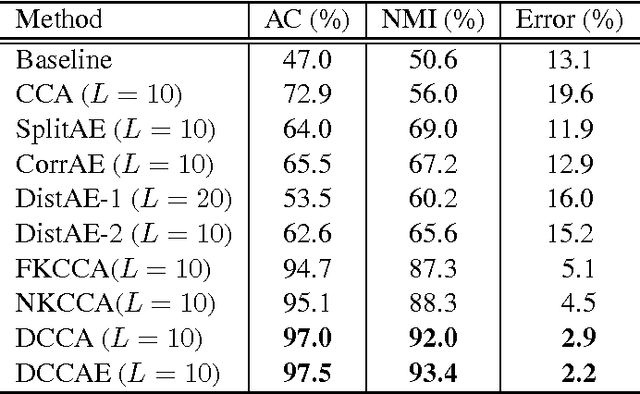

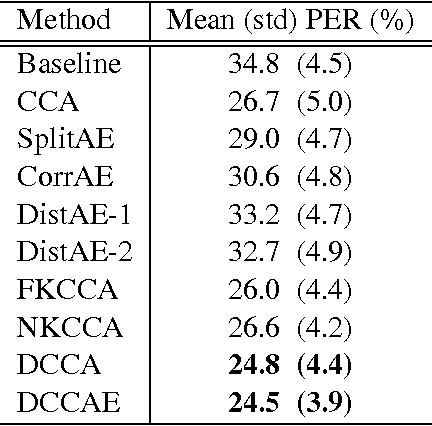
We consider learning representations (features) in the setting in which we have access to multiple unlabeled views of the data for learning while only one view is available for downstream tasks. Previous work on this problem has proposed several techniques based on deep neural networks, typically involving either autoencoder-like networks with a reconstruction objective or paired feedforward networks with a batch-style correlation-based objective. We analyze several techniques based on prior work, as well as new variants, and compare them empirically on image, speech, and text tasks. We find an advantage for correlation-based representation learning, while the best results on most tasks are obtained with our new variant, deep canonically correlated autoencoders (DCCAE). We also explore a stochastic optimization procedure for minibatch correlation-based objectives and discuss the time/performance trade-offs for kernel-based and neural network-based implementations.