Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Character-level Document Classification by Combining Convolution and Recurrent Layers
Paper and Code
Feb 01, 2016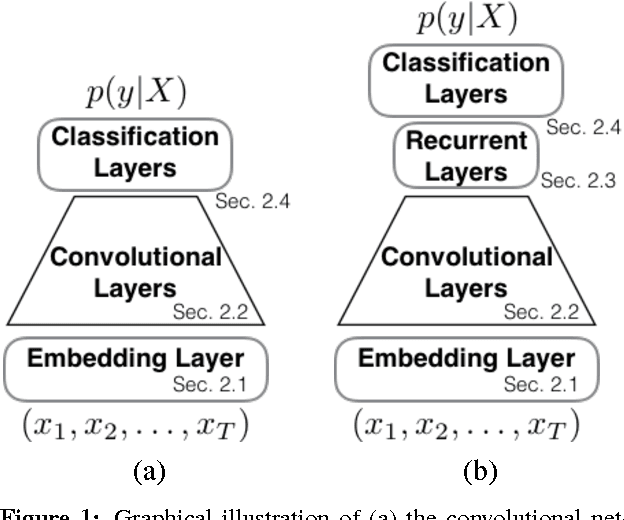
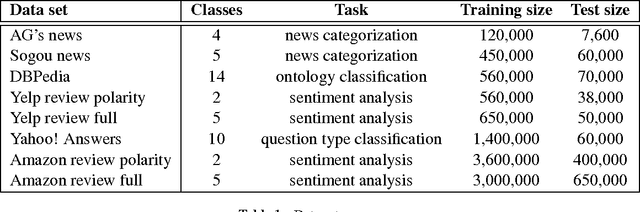
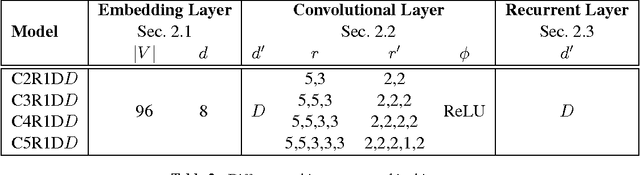
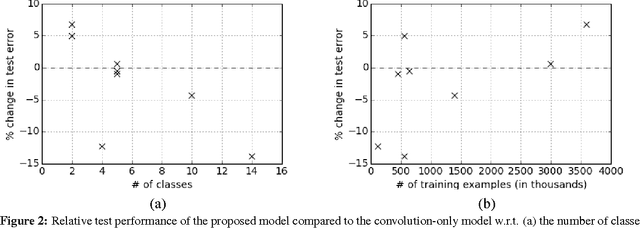
Document classification tasks were primarily tackled at word level. Recent research that works with character-level inputs shows several benefits over word-level approaches such as natural incorporation of morphemes and better handling of rare words. We propose a neural network architecture that utilizes both convolution and recurrent layers to efficiently encode character inputs. We validate the proposed model on eight large scale document classification tasks and compare with character-level convolution-only models. It achieves comparable performances with much less parameters.
View paper on