 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo Less and Achieve More: Training CNNs for Action Recognition Utilizing Action Images from the Web
Paper and Code
Dec 22, 2015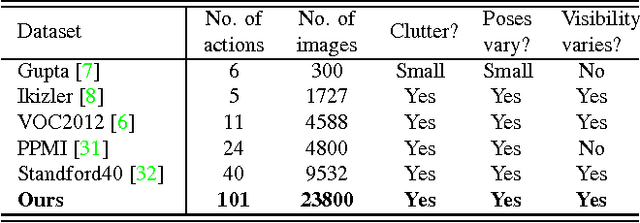

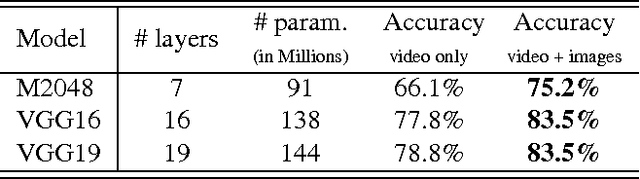
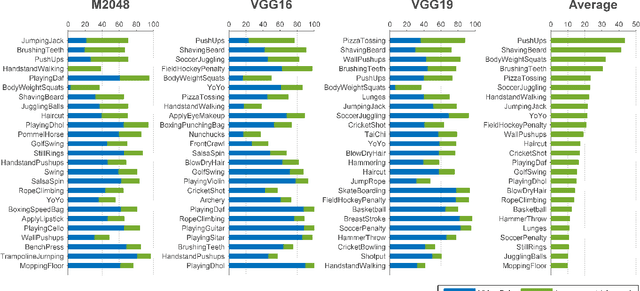
Recently, attempts have been made to collect millions of videos to train CNN models for action recognition in videos. However, curating such large-scale video datasets requires immense human labor, and training CNNs on millions of videos demands huge computational resources. In contrast, collecting action images from the Web is much easier and training on images requires much less computation. In addition, labeled web images tend to contain discriminative action poses, which highlight discriminative portions of a video's temporal progression. We explore the question of whether we can utilize web action images to train better CNN models for action recognition in videos. We collect 23.8K manually filtered images from the Web that depict the 101 actions in the UCF101 action video dataset. We show that by utilizing web action images along with videos in training, significant performance boosts of CNN models can be achieved. We then investigate the scalability of the process by leveraging crawled web images (unfiltered) for UCF101 and ActivityNet. We replace 16.2M video frames by 393K unfiltered images and get comparable performance.