Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBigger Buffer k-d Trees on Multi-Many-Core Systems
Paper and Code
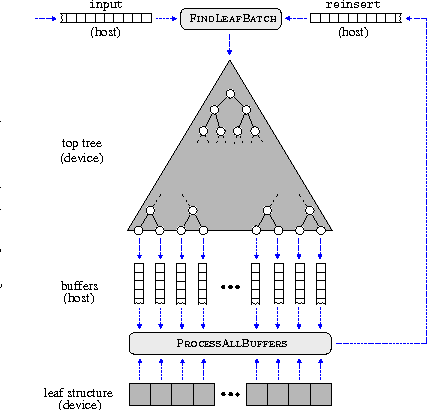
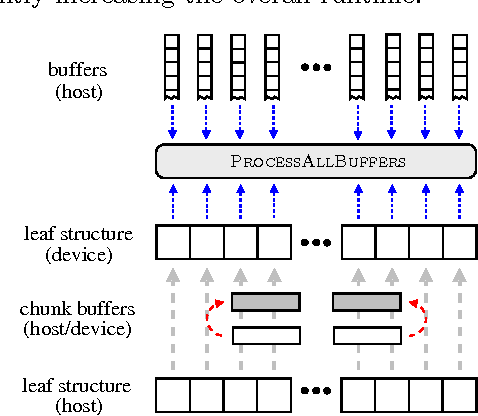
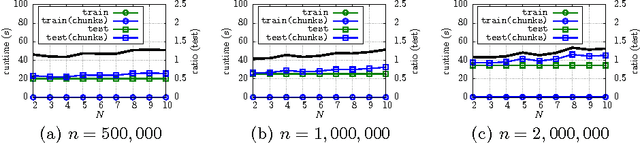

A buffer k-d tree is a k-d tree variant for massively-parallel nearest neighbor search. While providing valuable speed-ups on modern many-core devices in case both a large number of reference and query points are given, buffer k-d trees are limited by the amount of points that can fit on a single device. In this work, we show how to modify the original data structure and the associated workflow to make the overall approach capable of dealing with massive data sets. We further provide a simple yet efficient way of using multiple devices given in a single workstation. The applicability of the modified framework is demonstrated in the context of astronomy, a field that is faced with huge amounts of data.
View paper on