 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatio-temporal video autoencoder with differentiable memory
Paper and Code
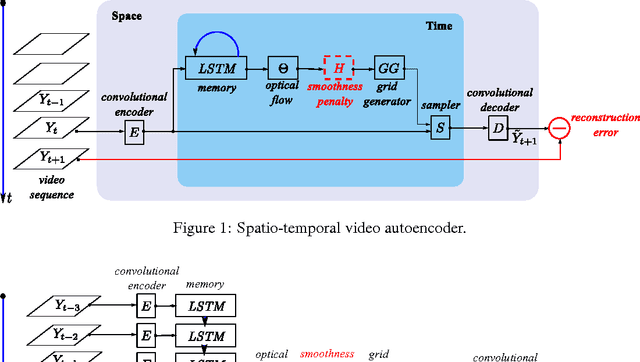
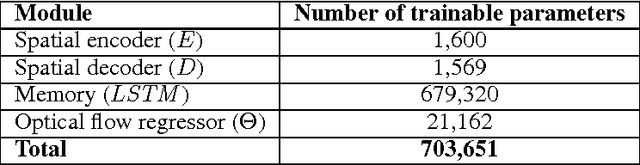


We describe a new spatio-temporal video autoencoder, based on a classic spatial image autoencoder and a novel nested temporal autoencoder. The temporal encoder is represented by a differentiable visual memory composed of convolutional long short-term memory (LSTM) cells that integrate changes over time. Here we target motion changes and use as temporal decoder a robust optical flow prediction module together with an image sampler serving as built-in feedback loop. The architecture is end-to-end differentiable. At each time step, the system receives as input a video frame, predicts the optical flow based on the current observation and the LSTM memory state as a dense transformation map, and applies it to the current frame to generate the next frame. By minimising the reconstruction error between the predicted next frame and the corresponding ground truth next frame, we train the whole system to extract features useful for motion estimation without any supervision effort. We present one direct application of the proposed framework in weakly-supervised semantic segmentation of videos through label propagation using optical flow.