Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproved Deep Learning Baselines for Ubuntu Corpus Dialogs
Paper and Code
Nov 03, 2015
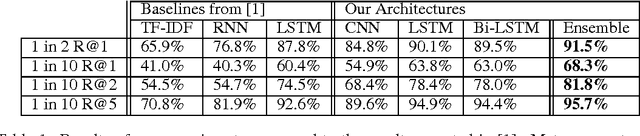
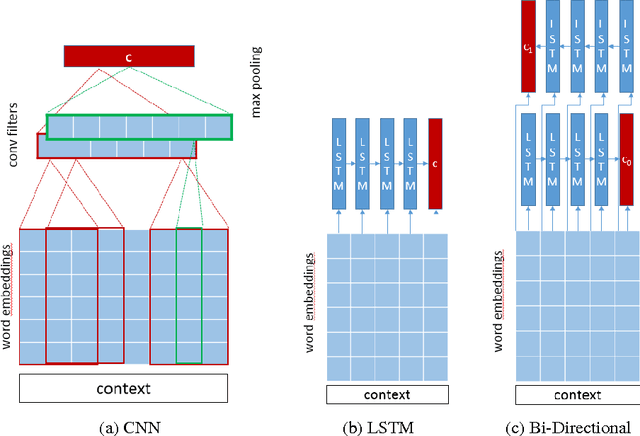
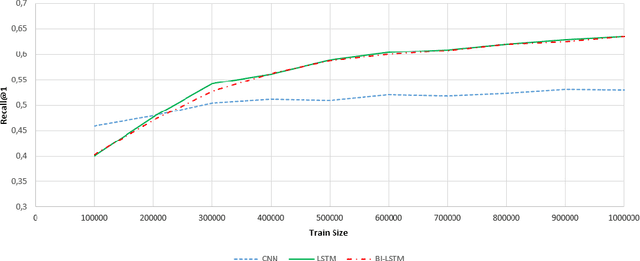
This paper presents results of our experiments for the next utterance ranking on the Ubuntu Dialog Corpus -- the largest publicly available multi-turn dialog corpus. First, we use an in-house implementation of previously reported models to do an independent evaluation using the same data. Second, we evaluate the performances of various LSTMs, Bi-LSTMs and CNNs on the dataset. Third, we create an ensemble by averaging predictions of multiple models. The ensemble further improves the performance and it achieves a state-of-the-art result for the next utterance ranking on this dataset. Finally, we discuss our future plans using this corpus.
* Accepted to Machine Learning for SLU & Interaction NIPS 2015 Workshop
View paper on