 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA new boosting algorithm based on dual averaging scheme
Paper and Code
Jul 11, 2015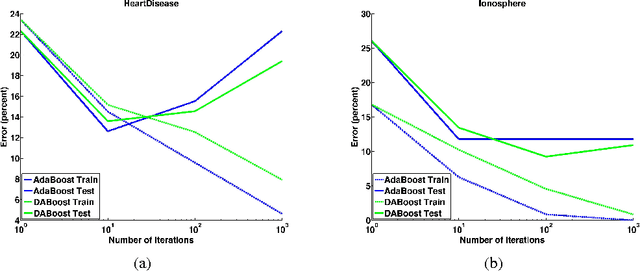
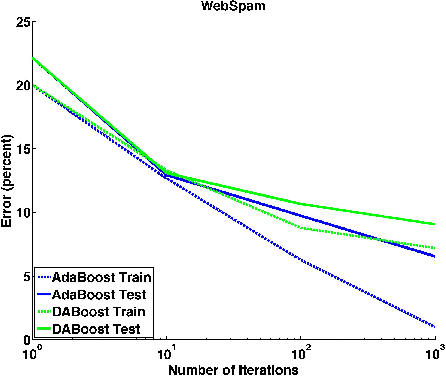
The fields of machine learning and mathematical optimization increasingly intertwined. The special topic on supervised learning and convex optimization examines this interplay. The training part of most supervised learning algorithms can usually be reduced to an optimization problem that minimizes a loss between model predictions and training data. While most optimization techniques focus on accuracy and speed of convergence, the qualities of good optimization algorithm from the machine learning perspective can be quite different since machine learning is more than fitting the data. Better optimization algorithms that minimize the training loss can possibly give very poor generalization performance. In this paper, we examine a particular kind of machine learning algorithm, boosting, whose training process can be viewed as functional coordinate descent on the exponential loss. We study the relation between optimization techniques and machine learning by implementing a new boosting algorithm. DABoost, based on dual-averaging scheme and study its generalization performance. We show that DABoost, although slower in reducing the training error, in general enjoys a better generalization error than AdaBoost.